This function is used to select the optimal values for parameters slices and alpha in weighted sliced inverse regression based on your provided gene expression data and corresponding spatial coordinates. For a given evaluation metric, it will visualise the performance of WSIR with varying function parameters based on your data, and return the optimal pair. This pair of slices and alpha can be used for your downstream tasks.
Usage
exploreWSIRParams(
X,
coords,
samples = rep(1, nrow(coords)),
optim_alpha = c(0, 2, 4, 10),
optim_slices = c(5, 10, 15, 20),
metric = "DC",
n_rep = 50,
plot = TRUE,
verbose = TRUE,
BPPARAM = BiocParallel::SerialParam(RNGseed = .Random.seed[1]),
...
)Arguments
- X
matrix containing normalised gene expression data including n cells and p genes, dimension n * p.
- coords
dataframe containing spatial positions of n cells in 2D space. Dimension n * 2. Column names must be c("x", "y").
- samples
sample ID of each cell. In total, must have length equal to the number of cells. For example, if your dataset has 10000 cells, the first 5000 from sample 1 and the remaining 5000 from sample 2, you would write samples = c(rep(1, 5000), rep(2, 5000)) to specify that the first 5000 cells are sample 1 and the remaining are sample 2. Default is that all cells are from sample 1. Sample IDs can be of any format: for the previous example, you could write samples = c(rep("sample 1", 5000), rep("sample 2", 5000)), and the result would be the same.
- optim_alpha
vector of numbers as the values of parameter alpha to use in WSIR. 0 gives Sliced Inverse Regression (SIR) implementation, and larger values represent stronger spatial correlation. Suggest to use integers for interpretability, but can use non-integers. Values must be non-negative.
- optim_slices
vector of integers as the values of parameter slices to use in WSIR. Suggest maximum value in the vector to be no more than around \(\sqrt{n/20}\), as this upper bound ensures an average of at least 10 cells per tile in the training set.
- metric
character single value. Evaluation metric to use for parameter tuning to select optimal parameter combination. String, use "DC" to use distance correlation, "CD" to use correlation of distances, or "ncol" for the number of dimensions in the low-dimensional embedding. Default is "DC".
- n_rep
integer for the number of train/test splits of the data to perform.
- plot
logical whether a dotplot of parameters and metrics should be produced, default TRUE
- verbose
default TRUE
- BPPARAM
Optional parallel computing instance as in
BiocParallelParamto be used inBiocParallel::bplapply. Default isBiocParallelParaminstance with one core.- ...
arguments passed on to wSIROptimisation
Value
List with five slots, named "plot", "message", "best_alpha", "best_slices" and "results_dataframe".
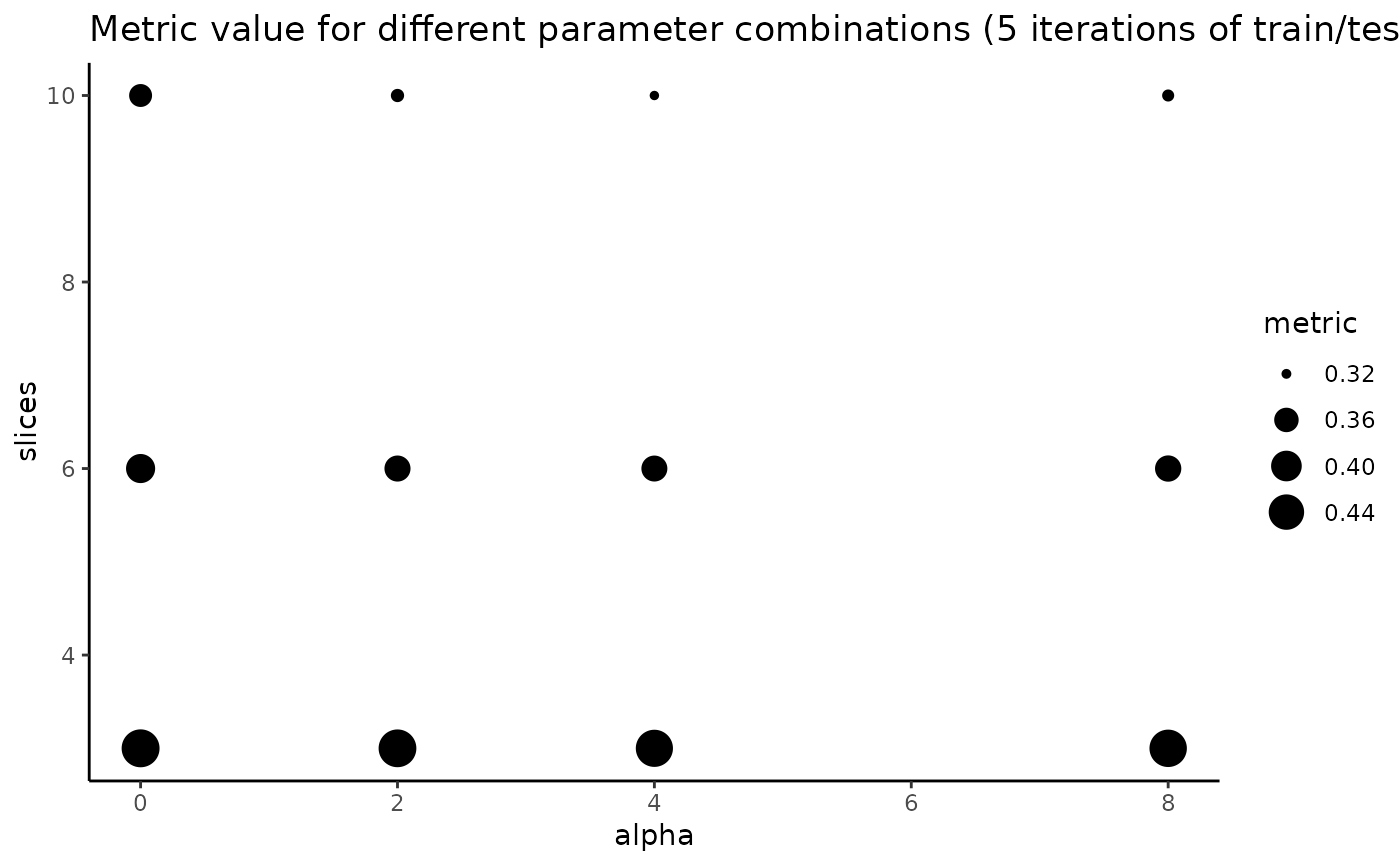
"plot" shows the average metric value across the n_rep iterations for every combination of parameters slices and alpha. Larger circles for a slices/alpha combination indicates better performance for that pair of values. There is one panel per evaluation metric selected in "metrics" argument.
"message" tells you the parameter combination with highest metric value according to selected metric.
"best_alpha" returns the integer for the best alpha values among the values that were tested according to selected metric.
"best_slices" returns the integer for the best slices value among the values that were tested according to selected metric.
"results_dataframe" returns the results dataframe used to create "plot". This dataframe has length(optim_alpha)*length(optim_slices) rows, where one is for each combination of parameters slices and alpha. There is one column for "alpha", one for "slices" and one for each of the evaluation metrics selected in "metrics" argument. Column "alpha" includes the value for parameter alpha, column "slices" includes the value for parameter slices, and each metric column includes the value for the specified metric, which is either Distance Correlation ("DC"), Correlation of Distances ("CD"), or number of columns in low-dimensional embedding ("ncol").
Examples
data(MouseData)
explore_params = exploreWSIRParams(X = sample1_exprs,
coords = sample1_coords,
optim_alpha = c(0,4),
optim_slices = c(3,6))
#> set up n_rep random splits of the data into training and test sets
#> completed runs of wSIR and metric calculation
#> Optimal (alpha, slices) pair: (0, 3)
explore_params$plot
 explore_params$message
#> [1] "Optimal (alpha, slices) pair: (0, 3)"
best_alpha = explore_params$best_alpha
best_slices = explore_params$best_slices
wsir_obj = wSIR(X = sample1_exprs,
coords = sample1_coords,
optim_params = FALSE,
alpha = best_alpha,
slices = best_slices)
explore_params$message
#> [1] "Optimal (alpha, slices) pair: (0, 3)"
best_alpha = explore_params$best_alpha
best_slices = explore_params$best_slices
wsir_obj = wSIR(X = sample1_exprs,
coords = sample1_coords,
optim_params = FALSE,
alpha = best_alpha,
slices = best_slices)