Performing a spatial analysis of multiplexed tissue imaging data.
Alexander Nicholls
Westmead Institute for Medical Research, University of Sydney, AustraliaNicholas Robertson
School of Mathematics and Statistics, University of Sydney, AustraliaNicholas Canete
Westmead Institute for Medical Research, University of Sydney, AustraliaElijah Willie
Westmead Institute for Medical Research, University of Sydney, AustraliaSchool of Mathematics and Statistics, University of Sydney, AustraliaEllis Patrick
Westmead Institute for Medical Research, University of Sydney, AustraliaSchool of Mathematics and Statistics, University of Sydney, Australia27 July, 2022
Source:vignettes/spicyWorkflow.Rmd
spicyWorkflow.RmdVersion Info
R version: R version 4.3.0 alpha (2023-03-29 r84123)
Bioconductor version: 3.17
Understanding the interplay between different types of cells and their immediate environment is critical for understanding the mechanisms of cells themselves and their function in the context of human diseases. Recent advances in high dimensional in situ cytometry technologies have fundamentally revolutionised our ability to observe these complex cellular relationships providing an unprecedented characterisation of cellular heterogeneity in a tissue environment.
We have developed an analytical framework for analysing data from high dimensional in situ cytometry assays including CODEX, CycIF, IMC and High Definition Spatial Transcriptomics. Implemented in R, this framework makes use of functionality from our Bioconductor packages spicyR, lisaClust, treekoR, FuseSOM, simpleSeg and ClassifyR. Below we will provide an overview of key steps which are needed to interrogate the comprehensive spatial information generated by these exciting new technologies including cell segmentation, feature normalisation, cell type identification, micro-environment characterisation, spatial hypothesis testing and patient classification. Ultimately, our modular analysis framework provides a cohesive and accessible entry point into spatially resolved single cell data analysis for any R-based bioinformatics.
Installation
To install the current release of spicyWorkflow, run the following code.
if (!require("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("spicyWorkflow")Global paramaters
It is convenient to set the number of cores for running code in parallel. Please choose a number that is appropriate for your resources.
nCores <- max(parallel::detectCores() - 1, 1)
BPPARAM <- simpleSeg:::generateBPParam(nCores)
theme_set(theme_classic())Context
In the following we will re-analyse some MIBI-TOF data (Risom et al, 2022) profiling the spatial landscape of ductal carcinoma in situ (DCIS), which is a pre-invasive lesion that is thought to be a precursor to invasive breast cancer (IBC). The key conclusion of this manuscript (amongst others) is that spatial information about cells can be used to predict disease progression in patients. We will use our spicy workflow to make a similar conclusion.
The R code for this analysis is available on github https://github.com/SydneyBioX/spicyWorkflow. A mildly processed version of the data used in the manuscript is available in this repository.
Read in images
The images are stored in the images folder within the data folder. Here we use loadImages() from the cytomapper package to load all the tiff images into a CytoImageList object and store the images as h5 file on-disk.
pathToImages <- system.file("extdata/images", package = "spicyWorkflow")
# Store images in a CytoImageList with images on_disk as h5 files to save memory.
images <- cytomapper::loadImages(
pathToImages,
single_channel = TRUE,
on_disk = TRUE,
h5FilesPath = HDF5Array::getHDF5DumpDir(),
BPPARAM = BPPARAM
)
gc()## used (Mb) gc trigger (Mb) max used (Mb)
## Ncells 11340591 605.7 19359011 1033.9 14908772 796.3
## Vcells 18692386 142.7 33938162 259.0 23445664 178.9Load the clinical data
To associate features in our image with disease progression, it is important to read in information which links image identifiers to their progression status. We will do this here, making sure that our imageID match. ## Read the clinical data
# Read in clinical data, manipulate imageID and select columns
clinical <- read.csv(
system.file(
"extdata/1-s2.0-S0092867421014860-mmc1.csv",
package = "spicyWorkflow"
)
)
clinical <- clinical |>
mutate(imageID = paste0("Point", PointNumber, "_pt", Patient_ID, "_", TMAD_Patient))
clinical$imageID[grep("normal", clinical$Tissue_Type)] <- paste0(clinical$imageID[grep("normal", clinical$Tissue_Type)], "_Normal")
clinicalVariables <- c("imageID", "Patient_ID", "Status", "Age", "SUBTYPE", "PAM50", "Treatment", "DCIS_grade", "Necrosis")
rownames(clinical) <- clinical$imageIDSimpleSeg: Segment the cells in the images
Our simpleSeg R package on https://github.com/SydneyBioX/simpleSeg provides a series of functions to generate simple segmentation masks of images. These functions leverage the functionality of the EBImage package on Bioconductor. For more flexibility when performing your segmentation in R we recommend learning to use the EBimage package. A key strength of the simpleSeg package is that we have coded multiple ways to perform some simple segmentation operations as well as incorporating multiple automatic procedures to optimise some key parameters when these aren’t specified.
Run simpleSeg
If your images are stored in a list or CytoImageList they can be segmented with a simple call to simpleSeg(). Here we have ask simpleSeg to do multiple things. First, we would like to use a combination of principal component analysis of all channels guided by the H33 channel to summarise the nuclei signal in the images. Secondly, to estimate the cell body of the cells we will simply dilate out from the nuclei by 2 pixels. We have also requested that the channels be square root transformed and that a minimum cell size of 40 pixels be used as a size selection step.
Visualise separation
The display and colorLabels functions in EBImage make it very easy to examine the performance of the cell segmentation. The great thing about display is that if used in an interactive session it is very easy to zoom in and out of the image.
# Visualise segmentation performance one way.
EBImage::display(colorLabels(masks[[1]]))
Visualise outlines
The plotPixels function in cytomapper make it easy to overlay the masks on top of the intensities of 6 markers. Here we can see that the segmentation appears to be performing reasonably.
# Visualise segmentation performance another way.
cytomapper::plotPixels(
image = images[1],
mask = masks[1],
img_id = "imageID",
colour_by = c("PanKRT", "GLUT1", "HH3", "CD3", "CD20"),
display = "single",
colour = list(
HH3 = c("black", "blue"),
CD3 = c("black", "purple"),
CD20 = c("black", "green"),
GLUT1 = c("black", "red"),
PanKRT = c("black", "yellow")
),
bcg = list(
HH3 = c(0, 1, 1.5),
CD3 = c(0, 1, 1.5),
CD20 = c(0, 1, 1.5),
GLUT1 = c(0, 1, 1.5),
PanKRT = c(0, 1, 1.5)
),
legend = NULL
)
Summarise cell features.
In order to characterise the phenotypes of each of the segmented cells, measureObjects from cytomapper will calculate the average intensity of each channel within each cell as well as a few morphological features. The channel intensities will be stored in the counts assay in a SingleCellExperiment. Information on the spatial location of each cell is stored in colData in the m.cx and m.cy columns. In addition to this, it will propagate the information we have store in the mcols of our CytoImageList in the colData of the resulting SingleCellExperiment.
# Summarise the expression of each marker in each cell
cells <- cytomapper::measureObjects(
masks,
images,
img_id = "imageID",
BPPARAM = BPPARAM
)Normalise data
We should check to see if the marker intensities of each cell require some form of transformation or normalisation. Here we extract the intensities from the counts assay. Looking at CK7 which should be expressed in the majority of the tumour cells, the intensities are clearly very skewed.
# Extract marker data and bind with information about images
df <- as.data.frame(cbind(colData(cells), t(assay(cells, "counts"))))
# Plots densities of CK7 for each image.
ggplot(df, aes(x = CK7, colour = imageID)) +
geom_density() +
theme(legend.position = "none")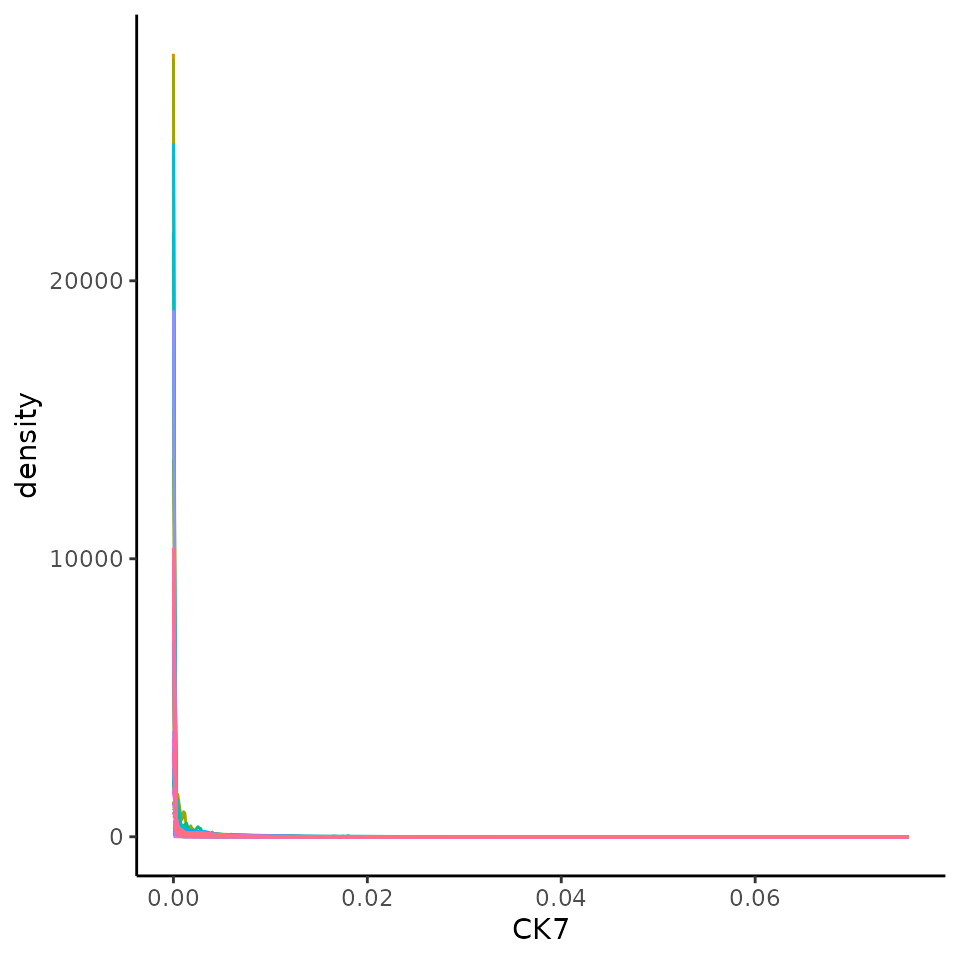
We can transform and normalise our data using the normalizeCells function. Here we have taken the intensities from the counts assay, performed a square root transform, then for each image trimmed the 99 quantile and min-max scaled to 0-1. This modified data is then stored in the norm assay by default. We can see that this normalised data appears more bimodal, not perfectly, but likely to a sufficient degree for clustering.
# Transform and normalise the marker expression of each cell type.
# Use a square root transform, then trimmed the 99 quantile
cells <- normalizeCells(cells,
transformation = "asinh",
method = c("trim99", "minMax", "PC1"),
assayIn = "counts",
cores = nCores
)
# Extract normalised marker information.
norm_df <- as.data.frame(cbind(colData(cells), t(assay(cells, "norm"))))
# Plots densities of normalised CK7 for each image.
ggplot(norm_df, aes(x = CK7, colour = imageID)) +
geom_density() +
theme(legend.position = "none")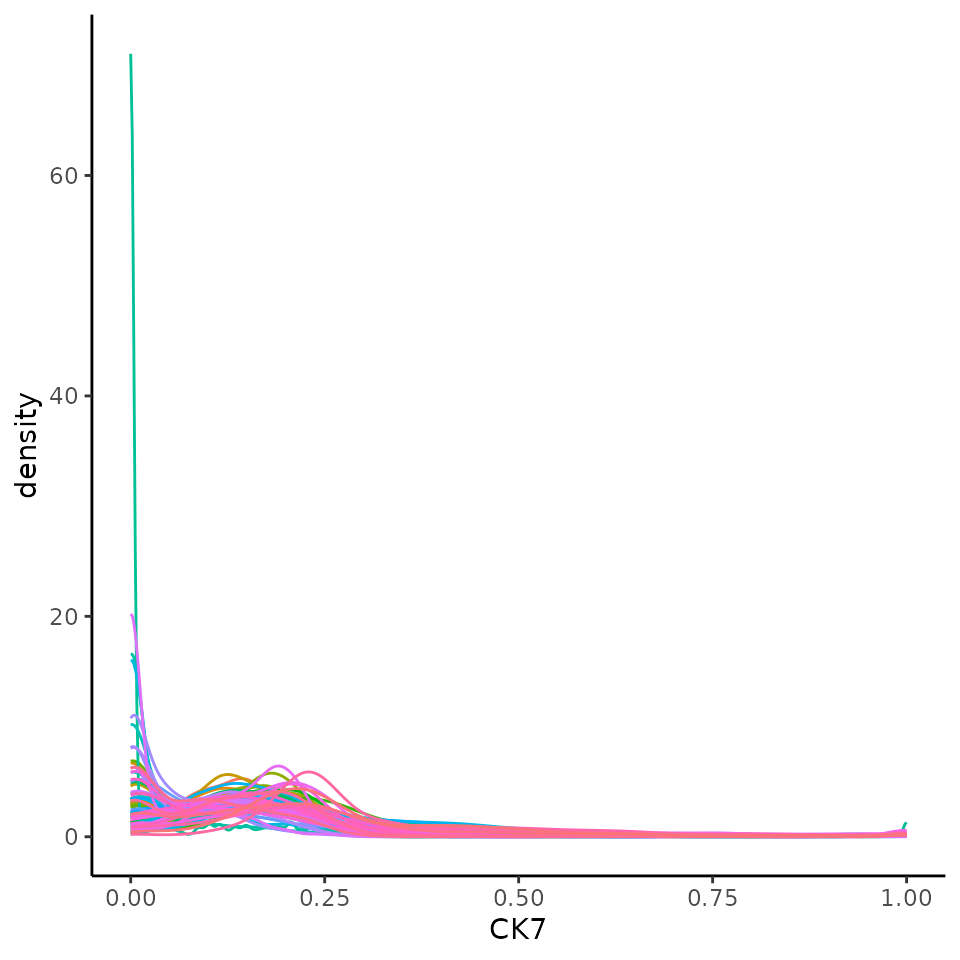
FuseSOM: Cluster cells into cell types
Our FuseSOM R package on https://github.com/ecool50/FuseSOM and provides a pipeline for the clustering of highly multiplexed in situ imaging cytometry assays. This pipeline uses the Self Organising Map architecture coupled with Multiview hierarchical clustering and provides functions for the estimation of the number of clusters.
Here we cluster using the runFuseSOM function. We have chosen to specify the same subset of markers used in the original manuscript for gating cell types. We have also specified the number of clusters to identify to be numClusters = 24. In addition to this, while FuseSOM can automatically estimate a grid size for the self organising map.
Perform the clustering
# The markers used in the original publication to gate cell types.
useMarkers <- c(
"PanKRT", "ECAD", "CK7", "VIM", "FAP", "CD31", "CK5", "SMA",
"CD45", "CD4", "CD3", "CD8", "CD20", "CD68", "CD14", "CD11c",
"HLADRDPDQ", "MPO", "Tryptase"
)
# Set seed.
set.seed(51773)
# Generate SOM and cluster cells into 20 groups.
cells <- runFuseSOM(
cells,
markers = useMarkers,
assay = "norm",
numClusters = 24
)Attempt to interpret the phenotype of each cluster
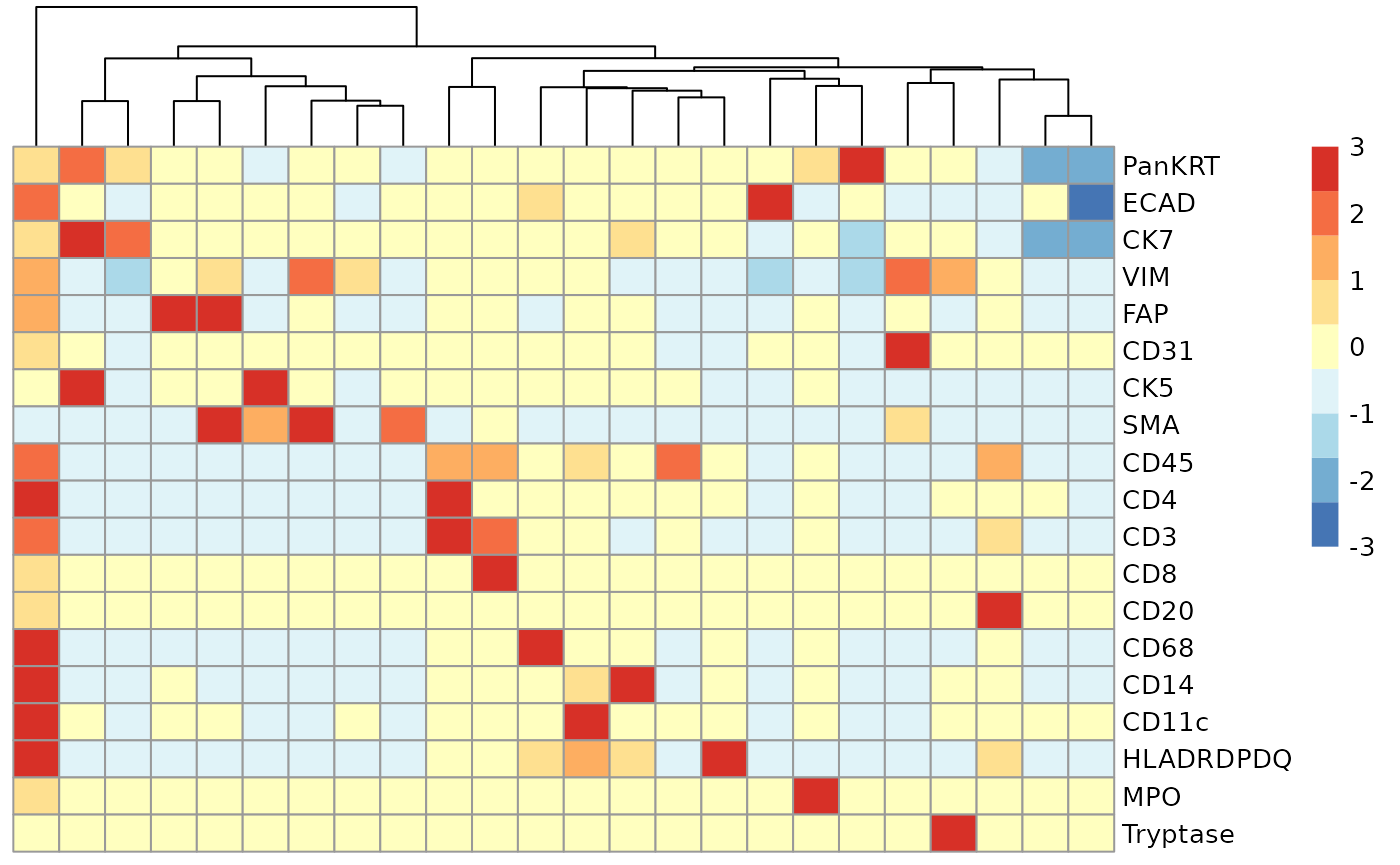
We can begin the process of understanding what each of these cell clusters are by using the plotGroupedHeatmap function from scater. At the least, here we can see we capture all the major immune populations that we expect to see.
# Visualise marker expression in each cluster.
scater::plotGroupedHeatmap(
cells,
features = useMarkers,
group = "clusters",
exprs_values = "norm",
center = TRUE,
scale = TRUE,
zlim = c(-3, 3),
cluster_rows = FALSE
)
Check how many clusters should be used.
We can check to see how reasonable our choice of 24 clusters is using the estimateNumCluster and the optiPlot functions. Here we examine the Gap method, others such as Silhouette and Within Cluster Distance are also available.
As we can be seen below, we chose the second elbow point as the optimal number of clusters.
# Generate metrics for estimating the number of clusters.
# As I've already run runFuseSOM I don't need to run generateSOM().
cells <- estimateNumCluster(cells, kSeq = 2:30)
optiPlot(cells, method = "gap")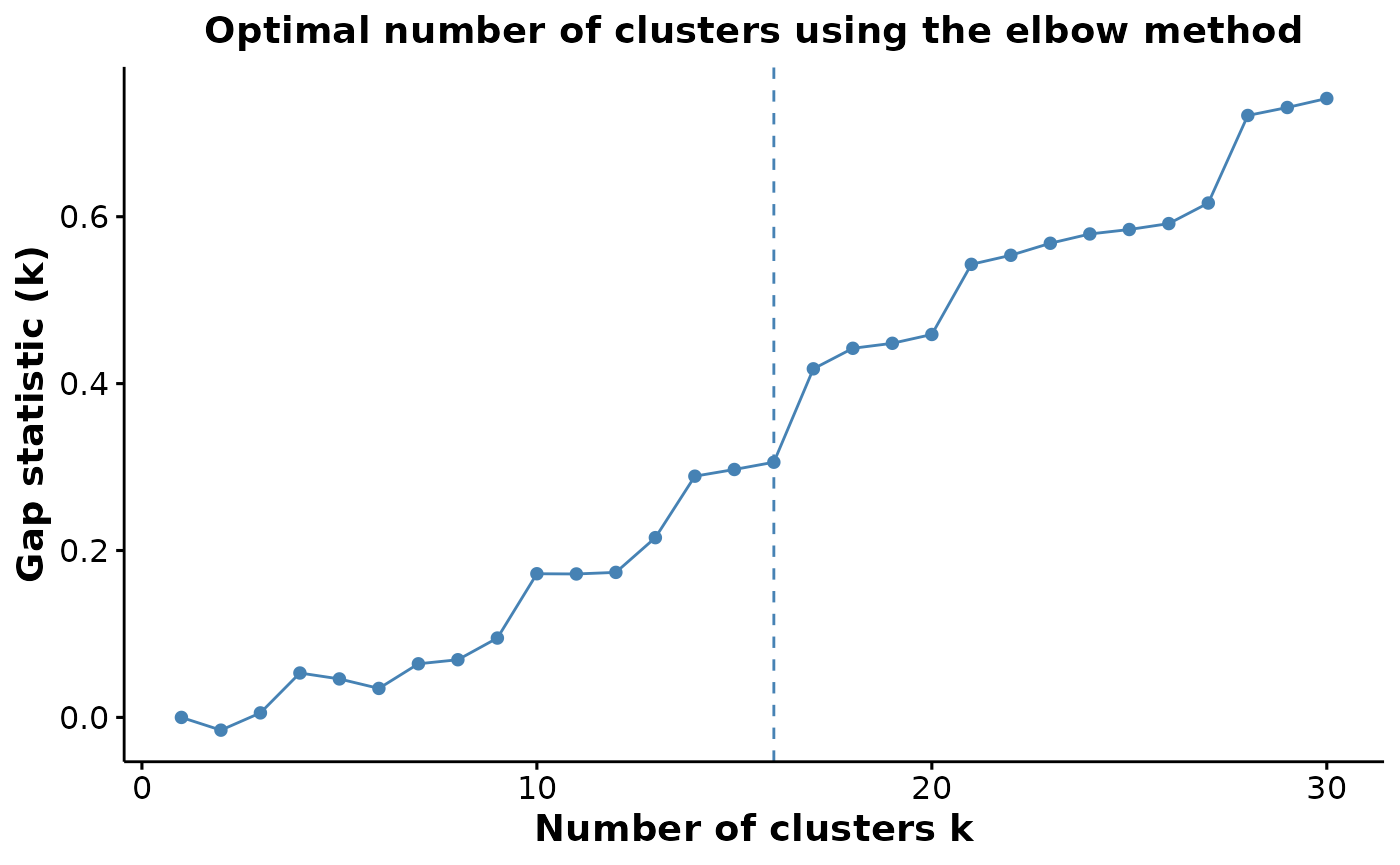
Check cluster frequencies
We find it always useful to check the number of cells in each cluster. Here we can see that cluster 4 is contains lots of (most likely tumour) cells and cluster 16 contains very few cells.
##
## cluster_17 cluster_9 cluster_21 cluster_7 cluster_12 cluster_3 cluster_2
## 205 254 358 593 664 695 711
## cluster_23 cluster_14 cluster_8 cluster_18 cluster_22 cluster_19 cluster_13
## 719 840 890 1019 1154 1236 1354
## cluster_1 cluster_10 cluster_16 cluster_11 cluster_20 cluster_24 cluster_15
## 1382 1431 1614 1871 3481 3965 4403
## cluster_5 cluster_4 cluster_6
## 6166 6551 19778Dimension reduction
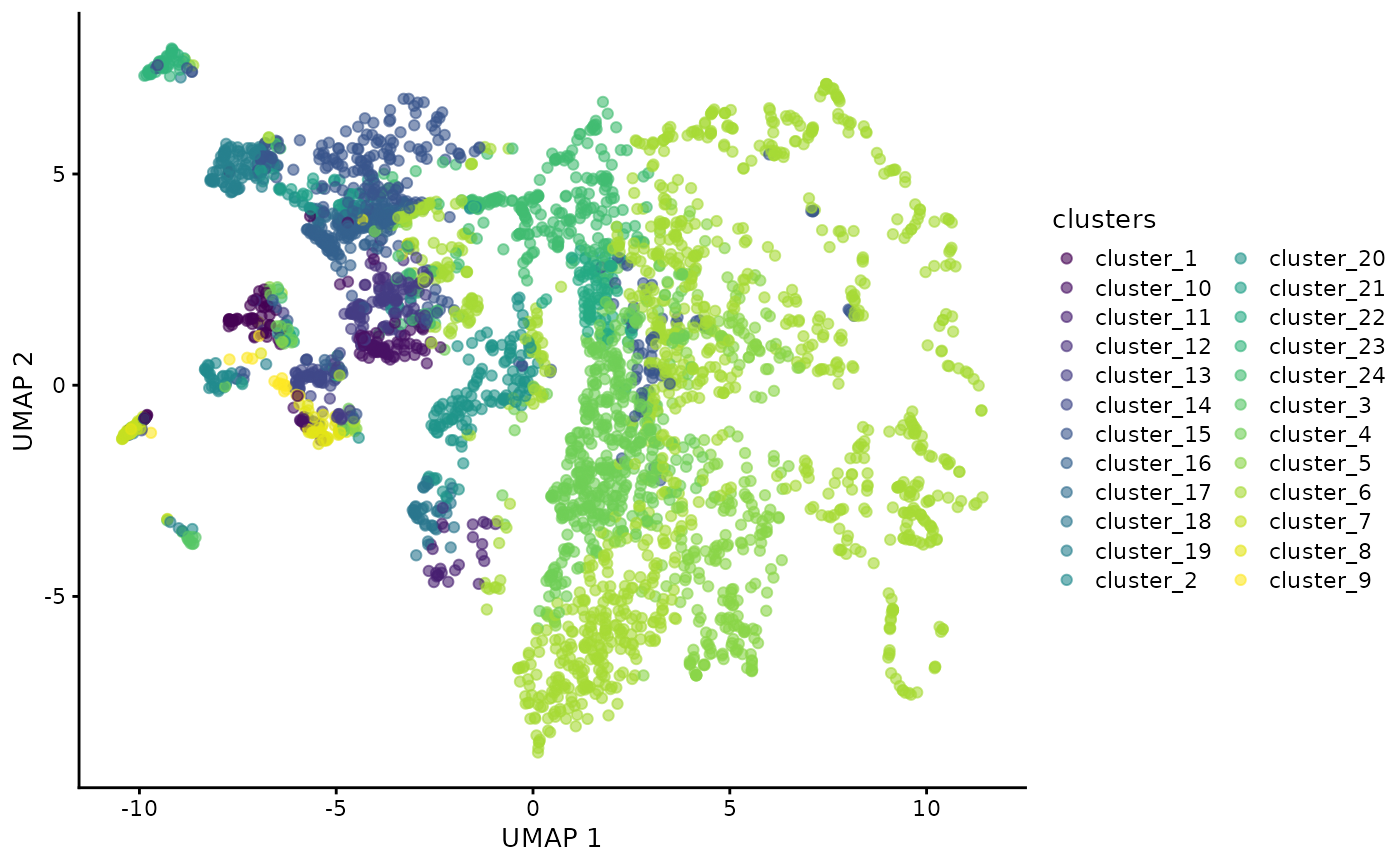
As our data is stored in a SingleCellExperiment we can also use scater to perform and visualise our data in a lower dimension to look for cluster differences.
set.seed(51773)
# Perform dimension reduction using UMP.
cells <- scater::runUMAP(
cells,
subset_row = useMarkers,
exprs_values = "norm"
)
# Select a subset of images to plot.
someImages <- unique(colData(cells)$imageID)[c(1, 10, 20, 40, 50, 60)]
# UMAP by cell type cluster.
scater::plotReducedDim(
cells[, colData(cells)$imageID %in% someImages],
dimred = "UMAP",
colour_by = "clusters"
)
Test For association between the proportion of each cell type and progression status
We recommend using a package such as diffcyt for testing for changes in abundance of cell types. However, the colTest function allows us to quickly test for associations between the proportions of the cell types and progression status using either Wilcoxon rank sum tests or t-tests. Here we see a p-value less than 0.05, but this does not equate to a small FDR.
# Select cells which belong to individuals with progressor status.
cellsToUse <- cells$Status %in% c("nonprogressor", "progressor")
# Perform simple wicoxon rank sum tests on the columns of the proportion matrix.
testProp <- colTest(cells[, cellsToUse],
condition = "Status",
feature = "clusters"
)
testProp## mean in group nonprogressor mean in group progressor t pval
## cluster_18 0.0210 0.0120 2.500 0.016
## cluster_15 0.0780 0.0590 1.900 0.063
## cluster_16 0.0270 0.0180 1.900 0.070
## cluster_3 0.0130 0.0034 1.800 0.074
## cluster_19 0.0230 0.0190 1.500 0.150
## cluster_17 0.0029 0.0016 1.400 0.170
## cluster_4 0.0980 0.1400 -1.400 0.170
## cluster_24 0.0590 0.0390 1.300 0.190
## cluster_9 0.0046 0.0027 1.300 0.210
## cluster_5 0.0960 0.1300 -1.100 0.270
## cluster_13 0.0220 0.0190 1.100 0.290
## cluster_10 0.0210 0.0280 -0.820 0.420
## cluster_11 0.0200 0.0250 -0.790 0.440
## cluster_6 0.3400 0.3200 0.770 0.450
## cluster_2 0.0100 0.0120 -0.740 0.470
## cluster_14 0.0120 0.0130 -0.520 0.610
## cluster_12 0.0110 0.0120 -0.510 0.620
## cluster_22 0.0180 0.0210 -0.420 0.680
## cluster_23 0.0130 0.0140 -0.420 0.680
## cluster_7 0.0093 0.0130 -0.400 0.690
## cluster_20 0.0540 0.0520 0.280 0.780
## cluster_8 0.0140 0.0150 -0.190 0.850
## cluster_1 0.0240 0.0230 0.140 0.890
## cluster_21 0.0066 0.0065 0.055 0.960
## adjPval cluster
## cluster_18 0.38 cluster_18
## cluster_15 0.44 cluster_15
## cluster_16 0.44 cluster_16
## cluster_3 0.44 cluster_3
## cluster_19 0.56 cluster_19
## cluster_17 0.56 cluster_17
## cluster_4 0.56 cluster_4
## cluster_24 0.56 cluster_24
## cluster_9 0.56 cluster_9
## cluster_5 0.63 cluster_5
## cluster_13 0.63 cluster_13
## cluster_10 0.75 cluster_10
## cluster_11 0.75 cluster_11
## cluster_6 0.75 cluster_6
## cluster_2 0.75 cluster_2
## cluster_14 0.83 cluster_14
## cluster_12 0.83 cluster_12
## cluster_22 0.83 cluster_22
## cluster_23 0.83 cluster_23
## cluster_7 0.83 cluster_7
## cluster_20 0.89 cluster_20
## cluster_8 0.93 cluster_8
## cluster_1 0.93 cluster_1
## cluster_21 0.96 cluster_21
imagesToUse <- rownames(clinical)[clinical[, "Status"] %in% c("nonprogressor", "progressor")]
prop <- getProp(cells, feature = "clusters")
clusterToUse <- rownames(testProp)[1]
boxplot(prop[imagesToUse, clusterToUse] ~ clinical[imagesToUse, "Status"])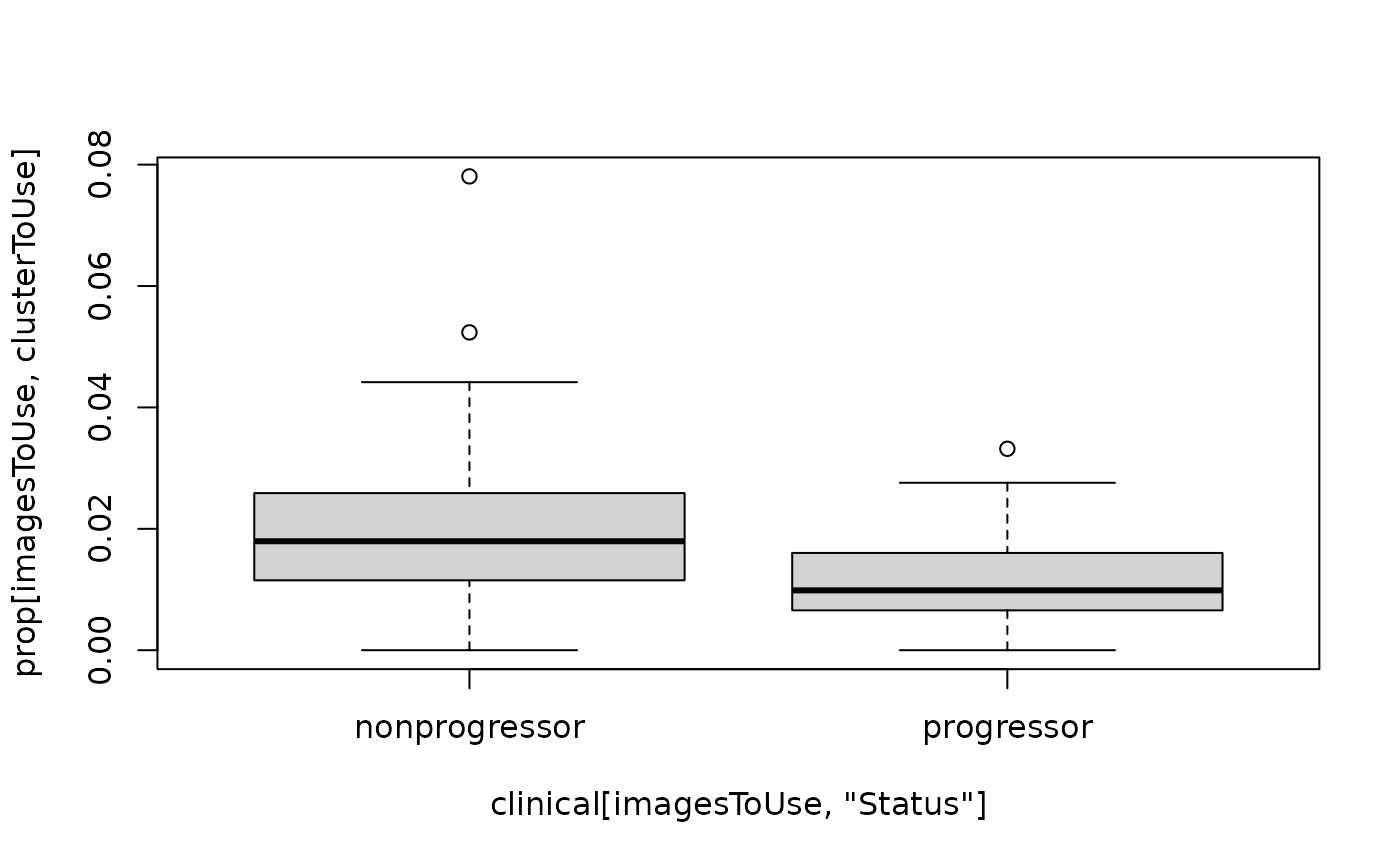
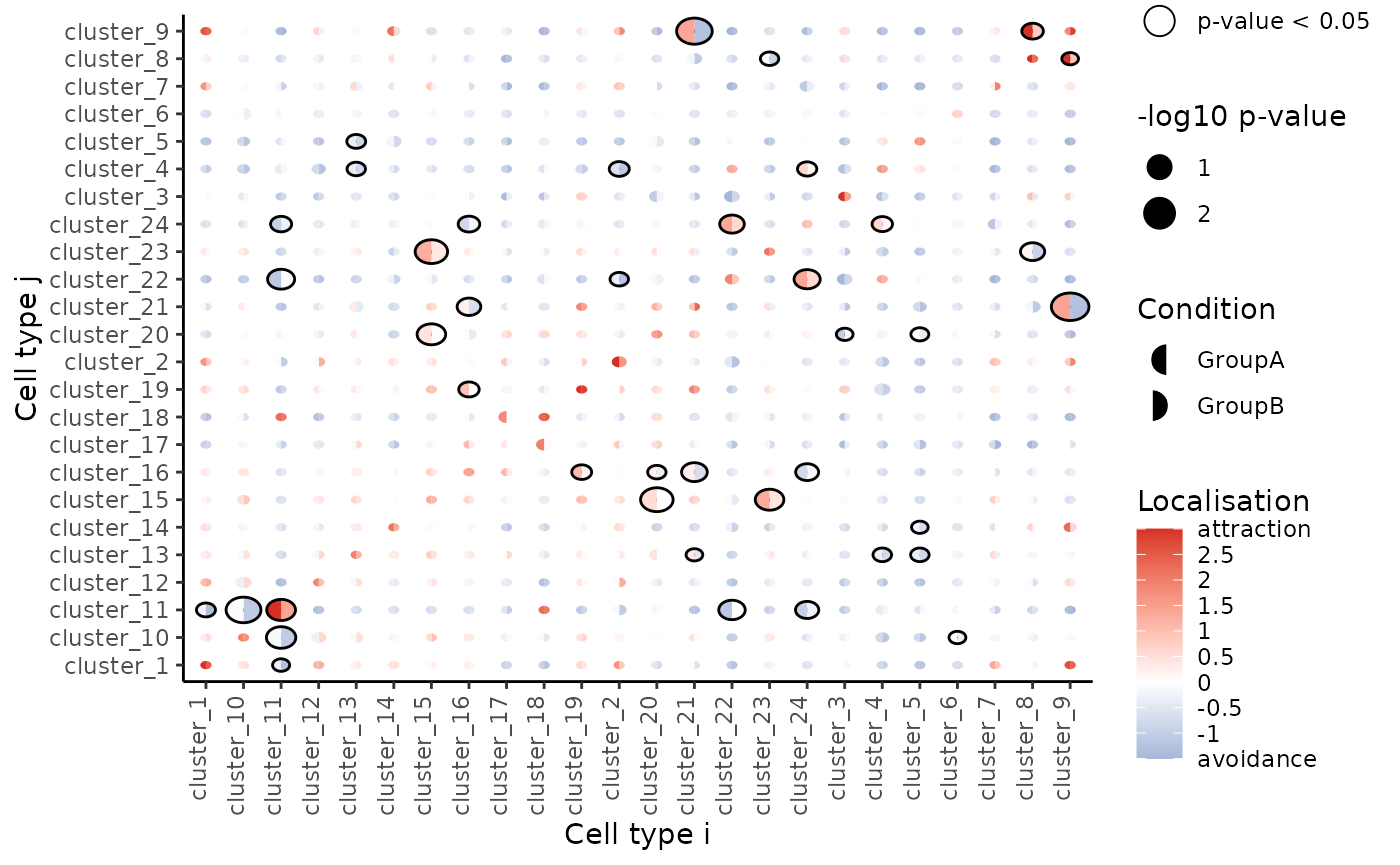
spicyR: test spatial relationships
Our spicyR package (https://www.bioconductor.org/packages/devel/bioc/html/spicyR.html)[https://www.bioconductor.org/packages/devel/bioc/html/spicyR.html] provides a series of functions to aid in the analysis of both immunofluorescence and mass cytometry imaging data as well as other assays that can deeply phenotype individual cells and their spatial location. Here we use the spicy function to test for changes in the spatial relationships between pair-wise combinations of cells. We quantify spatial relationships using a combination of three radii Rs = c(20, 50, 100) and mildly account for some global tissue structure using sigma = 50.
# Test for changes in pair-wise spatial relationships between cell types.
spicyTest <- spicy(
cells[, cellsToUse],
condition = "Status",
cellType = "clusters",
imageID = "imageID",
spatialCoords = c("m.cx", "m.cy"),
Rs = c(20, 50, 100),
sigma = 50,
BPPARAM = BPPARAM
)
topPairs(spicyTest, n = 10)## intercept coefficient p.value adj.pvalue
## cluster_9__cluster_21 -114.962528 243.01532 0.001061505 0.3131976
## cluster_21__cluster_9 -114.039961 238.67211 0.001519455 0.3131976
## cluster_10__cluster_11 -97.300723 91.72319 0.001739253 0.3131976
## cluster_20__cluster_15 1.381275 44.36284 0.002661354 0.3131976
## cluster_15__cluster_23 33.123975 80.55381 0.002718729 0.3131976
## cluster_11__cluster_10 -91.995699 82.85717 0.004711349 0.3514033
## cluster_11__cluster_11 123.810238 173.86550 0.005250569 0.3514033
## cluster_23__cluster_15 36.773523 80.07047 0.005467489 0.3514033
## cluster_15__cluster_20 -2.489198 39.95061 0.005490676 0.3514033
## cluster_11__cluster_22 -2.818209 -99.24727 0.007230443 0.4085725
## from to
## cluster_9__cluster_21 cluster_9 cluster_21
## cluster_21__cluster_9 cluster_21 cluster_9
## cluster_10__cluster_11 cluster_10 cluster_11
## cluster_20__cluster_15 cluster_20 cluster_15
## cluster_15__cluster_23 cluster_15 cluster_23
## cluster_11__cluster_10 cluster_11 cluster_10
## cluster_11__cluster_11 cluster_11 cluster_11
## cluster_23__cluster_15 cluster_23 cluster_15
## cluster_15__cluster_20 cluster_15 cluster_20
## cluster_11__cluster_22 cluster_11 cluster_22We can visualise these tests using signifPlot where we observe that cell type pairs appear to become less attractive (or avoid more) in the progression sample.
# Visualise which relationships are changing the most.
signifPlot(
spicyTest,
breaks = c(-1.5, 3, 0.5)
)
lisaClust: Find cellular neighbourhoods
Our lisaClust package (https://www.bioconductor.org/packages/devel/bioc/html/lisaClust.html)[https://www.bioconductor.org/packages/devel/bioc/html/lisaClust.html] provides a series of functions to identify and visualise regions of tissue where spatial associations between cell-types is similar. This package can be used to provide a high-level summary of cell-type co-localisation in multiplexed imaging data that has been segmented at a single-cell resolution. Here we use the lisaClust function to clusters cells into 5 regions with distinct spatial ordering.
set.seed(51773)
# Cluster cells into spatial regions with similar composition.
cells <- lisaClust(
cells,
k = 5,
Rs = c(20, 50, 100),
sigma = 50,
spatialCoords = c("m.cx", "m.cy"),
cellType = "clusters",
BPPARAM = BPPARAM
)Region - cell type enrichment heatmap
We can try to interpret which spatial orderings the regions are quantifying using the regionMap function. This plots the frequency of each cell type in a region relative to what you would expect by chance.
# Visualise the enrichment of each cell type in each region
regionMap(cells, cellType = "clusters", limit = c(0.2, 5))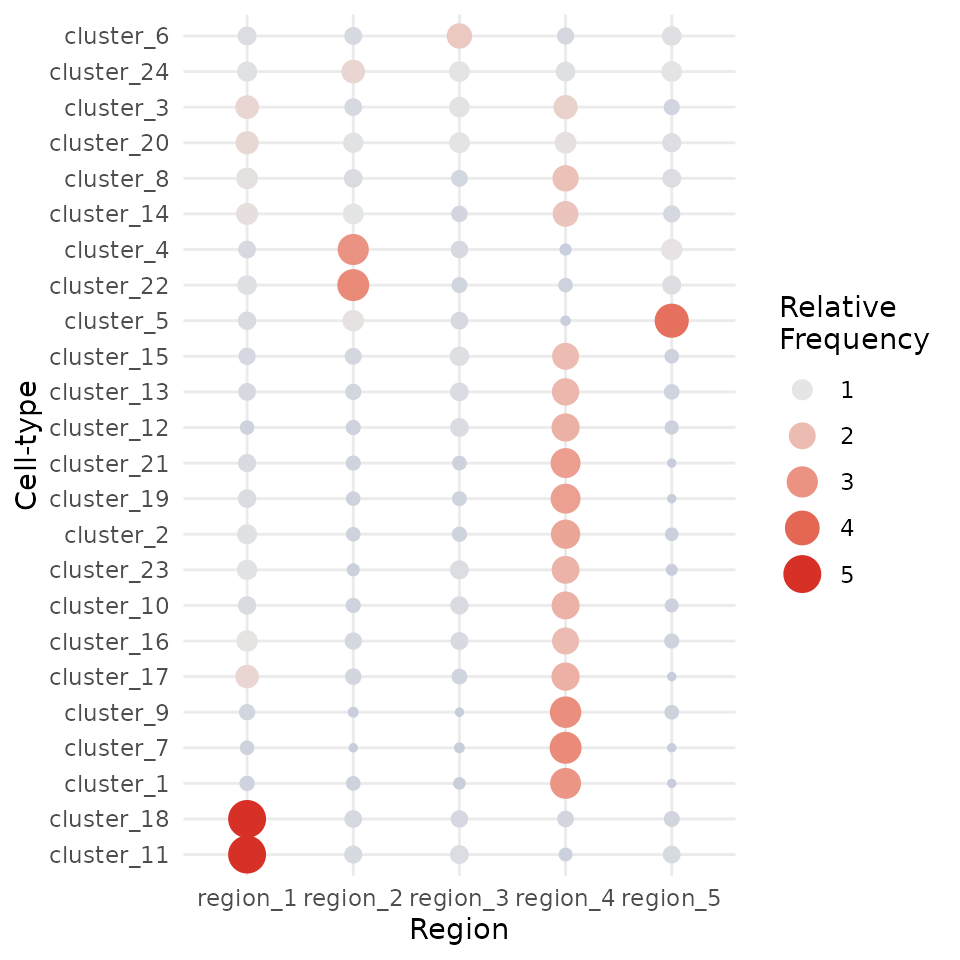
Visualise regions
By default, these identified regions are stored in the regions column in the colData of our object. We can quickly examine the spatial arrangement of these regions using ggplot.
# Extract cell information and filter to specific image.
df <- colData(cells) |>
as.data.frame() |>
filter(imageID == "Point2206_pt1116_31620")
# Colour cells by their region.
ggplot(df, aes(x = m.cx, y = m.cy, colour = region)) +
geom_point()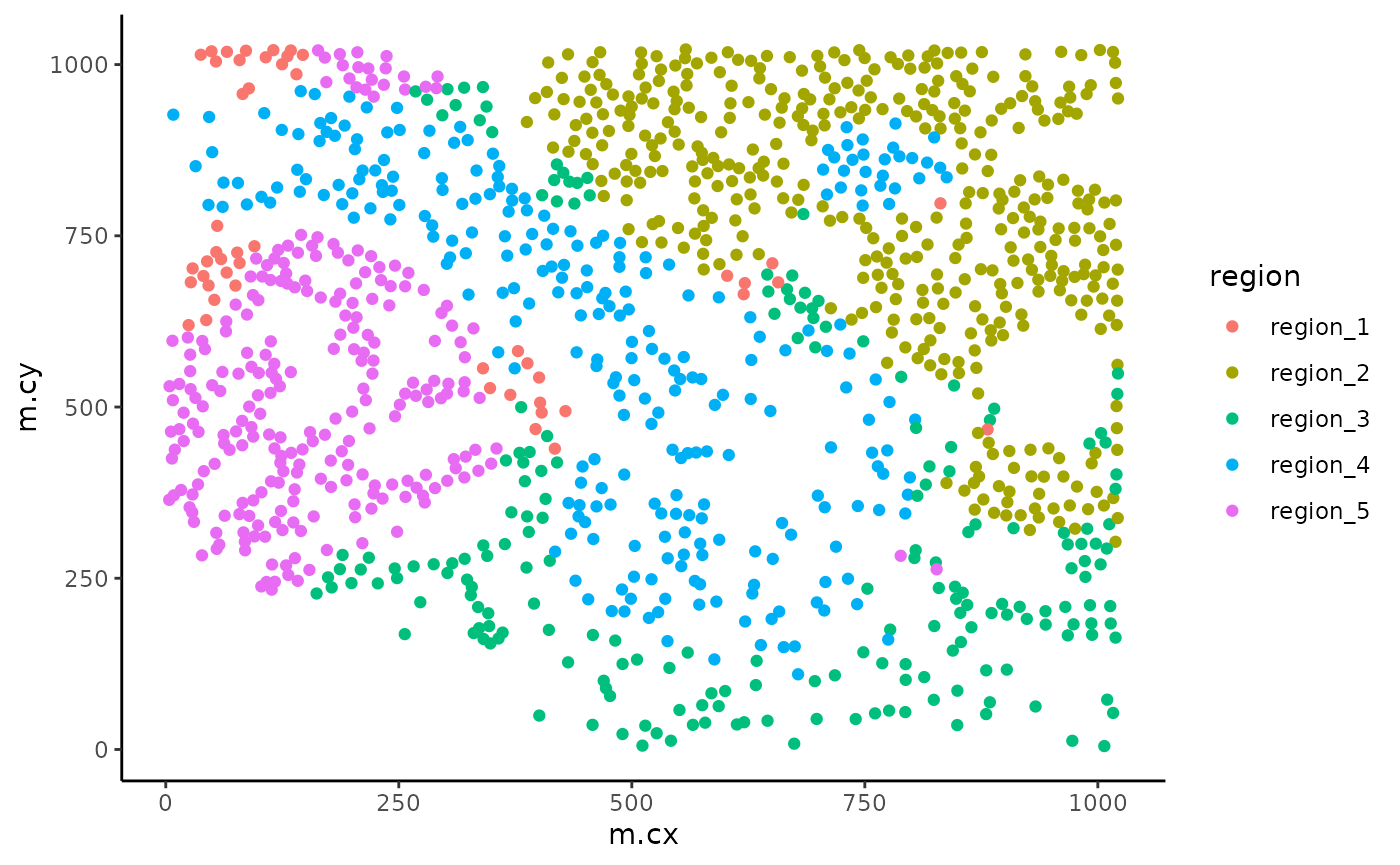
While much slower, we have also implemented a function for overlaying the region information as a hatching pattern so that the information can be viewed simultaneously with the cell type calls.
# Use hatching to visualise regions and cell types.
hatchingPlot(
cells,
useImages = "Point2206_pt1116_31620",
cellType = "clusters",
spatialCoords = c("m.cx", "m.cy")
)This plot is a ggplot object and so the scale can be modified with scale_region_manual.
# Use hatching to visualise regions and cell types.
# Relabel the hatching of the regions.
hatchingPlot(
cells,
useImages = "Point2206_pt1116_31620",
cellType = "clusters",
spatialCoords = c("m.cx", "m.cy"),
window = "square",
nbp = 300,
line.spacing = 41
) +
scale_region_manual(values = c(
region_1 = 2,
region_2 = 1,
region_3 = 5,
region_4 = 4,
region_5 = 3
)) +
guides(colour = guide_legend(ncol = 2))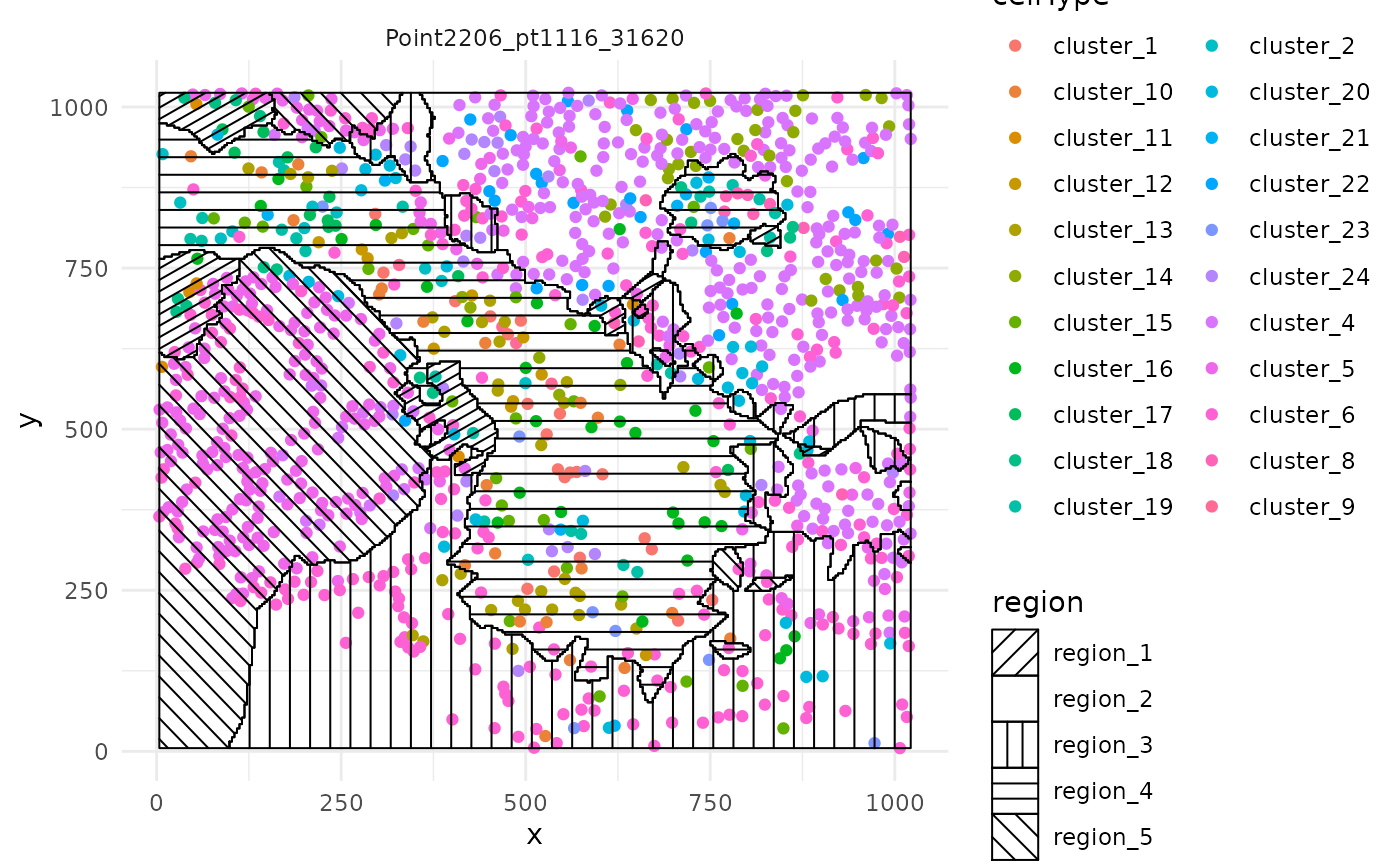
Test for association with progression
If needed, we can again quickly use the colTest function to test for associations between the proportions of the cells in each region and progression status using either Wilcoxon rank sum tests or t-tests. Here we see an adjusted p-value less than 0.05.
# Test if the proportion of each region is associated
# with progression status.
testRegion <- colTest(
cells[, cellsToUse],
feature = "region",
condition = "Status"
)
testRegion## mean in group nonprogressor mean in group progressor t pval
## region_3 0.330 0.290 1.60 0.11
## region_4 0.290 0.250 1.70 0.11
## region_5 0.120 0.170 -1.70 0.11
## region_2 0.180 0.220 -1.50 0.15
## region_1 0.082 0.081 0.03 0.98
## adjPval cluster
## region_3 0.18 region_3
## region_4 0.18 region_4
## region_5 0.18 region_5
## region_2 0.19 region_2
## region_1 0.98 region_1ClassifyR: Classification
Our ClassifyR package, https://github.com/SydneyBioX/ClassifyR, formalises a convenient framework for evaluating classification in R. We provide functionality to easily include four key modelling stages; Data transformation, feature selection, classifier training and prediction; into a cross-validation loop. Here we use the crossValidate function to perform 100 repeats of 5-fold cross-validation to evaluate the performance of an elastic net model applied to three quantification of our MIBI-TOF data; cell type proportions, average mean of each cell type and region proportions.
# Create list to store data.frames
data <- list()
# Add proportions of each cell type in each image
data[["props"]] <- getProp(cells, "clusters")
# Add pair-wise associations
data[["dist"]] <- getPairwise(
cells,
spatialCoords = c("m.cx", "m.cy"),
cellType = "clusters",
Rs = c(20, 50, 100),
sigma = 50,
BPPARAM = BPPARAM
)
data[["dist"]] <- as.data.frame(data[["dist"]])
# Add proportions of each region in each image
# to the list of dataframes.
data[["regions"]] <- getProp(cells, "region")
# Subset data images with progression status and NA clinical variables.
measurements <- lapply(data, function(x) x[imagesToUse, ])
# Set seed
set.seed(51773)
# Perform cross-validation of an elastic net model
# with 100 repeats of 5-fold cross-validation.
cv <- crossValidate(
measurements = measurements,
outcome = clinical[imagesToUse, "Status"],
classifier = "GLM",
nFolds = 5,
nRepeats = 100,
nCores = nCores
)Visualise cross-validated prediction performance
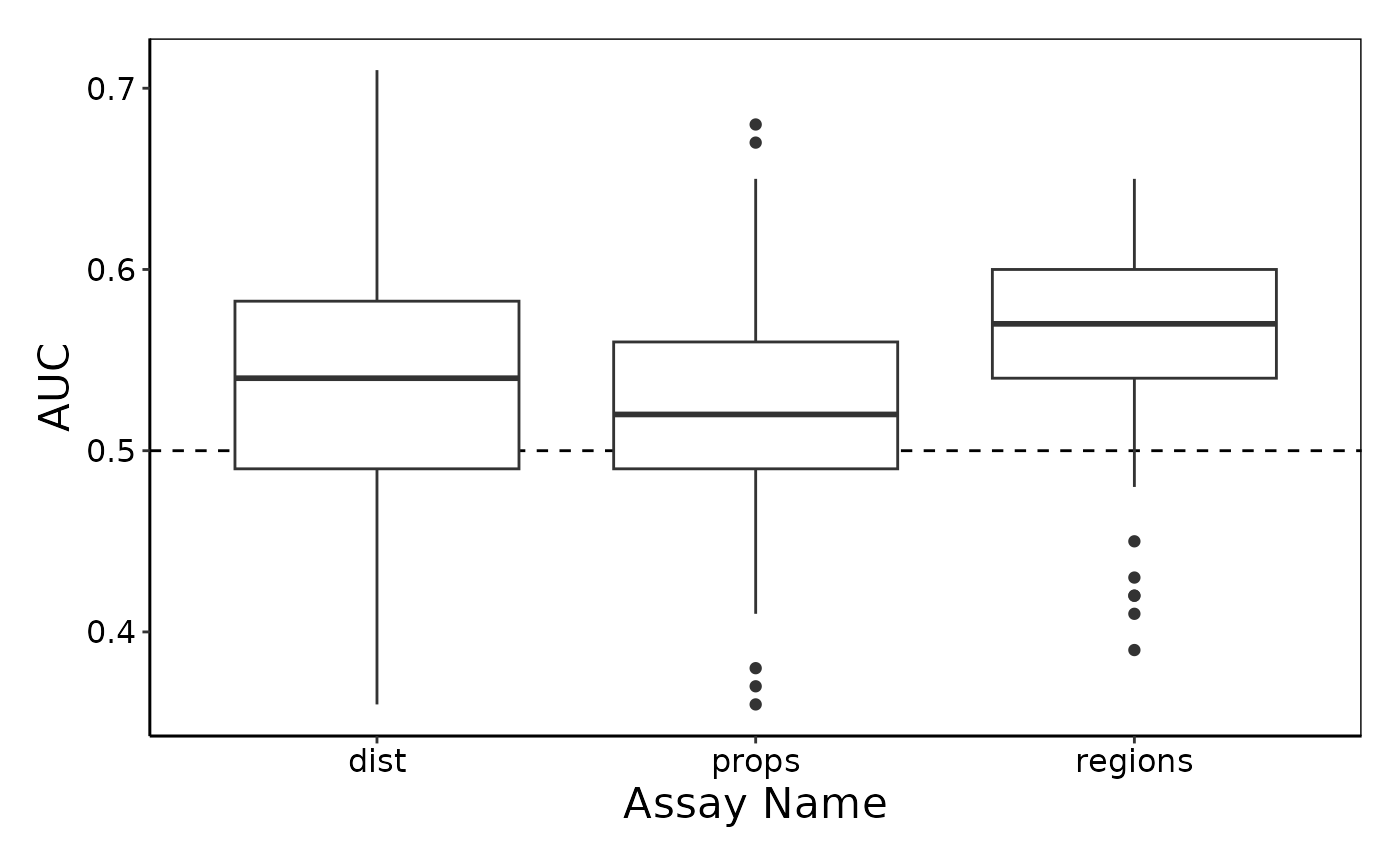
Here we use the performancePlot function to assess the AUC from each repeat of the 5-fold cross-validation. We see that the lisaClust regions appear to capture information which is predictive of progression status of the patients.
# Calculate AUC for each cross-validation repeat and plot.
performancePlot(
cv,
metric = "AUC",
characteristicsList = list(x = "Assay Name")
)
Summary
Here we have used a pipeline of our spatial analysis R packages to demonstrate an easy way to segment, cluster, normalise, quantify and classify high dimensional in situ cytometry data all within R.
sessionInfo
## R version 4.3.0 alpha (2023-03-29 r84123)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Debian GNU/Linux 11 (bullseye)
##
## Matrix products: default
## BLAS: /dora/nobackup/biostat/software/R-devel/lib/libRblas.so
## LAPACK: /dora/nobackup/biostat/software/R-devel/lib/libRlapack.so; LAPACK version 3.11.0
##
## locale:
## [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
## [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
## [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
## [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
##
## time zone: Australia/Sydney
## tzcode source: system (glibc)
##
## attached base packages:
## [1] stats4 stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] lisaClust_1.7.3 ClassifyR_3.3.25
## [3] survival_3.5-5 BiocParallel_1.33.12
## [5] MultiAssayExperiment_1.25.9 generics_0.1.3
## [7] spicyR_1.11.6 scater_1.27.8
## [9] scuttle_1.9.4 ggpubr_0.6.0
## [11] FuseSOM_1.1.3 simpleSeg_1.1.1
## [13] ggplot2_3.4.2 dplyr_1.1.1
## [15] cytomapper_1.11.2 SingleCellExperiment_1.21.1
## [17] SummarizedExperiment_1.29.1 Biobase_2.59.0
## [19] GenomicRanges_1.51.4 GenomeInfoDb_1.35.16
## [21] IRanges_2.33.1 S4Vectors_0.37.5
## [23] BiocGenerics_0.45.3 MatrixGenerics_1.11.1
## [25] matrixStats_0.63.0 EBImage_4.41.2
## [27] BiocStyle_2.27.1
##
## loaded via a namespace (and not attached):
## [1] fs_1.6.1 spatstat.sparse_3.0-1
## [3] bitops_1.0-7 httr_1.4.5
## [5] RColorBrewer_1.1-3 prabclus_2.3-2
## [7] DataVisualizations_1.2.3 numDeriv_2016.8-1.1
## [9] tools_4.3.0 backports_1.4.1
## [11] utf8_1.2.3 R6_2.5.1
## [13] vegan_2.6-4 HDF5Array_1.27.0
## [15] uwot_0.1.14 mgcv_1.8-42
## [17] rhdf5filters_1.11.2 permute_0.9-7
## [19] withr_2.5.0 sp_1.6-0
## [21] analogue_0.17-6 gridExtra_2.3
## [23] cli_3.6.1 textshaping_0.3.6
## [25] spatstat.explore_3.1-0 profileModel_0.6.1
## [27] labeling_0.4.2 sass_0.4.5
## [29] diptest_0.76-0 robustbase_0.95-1
## [31] brglm_0.7.2 nnls_1.4
## [33] spatstat.data_3.0-1 genefilter_1.81.3
## [35] proxy_0.4-27 pkgdown_2.0.7
## [37] systemfonts_1.0.4 yulab.utils_0.0.6
## [39] svglite_2.1.1 R.utils_2.12.2
## [41] limma_3.55.7 RSQLite_2.3.1
## [43] gridGraphics_0.5-1 spatstat.random_3.1-4
## [45] car_3.1-2 scam_1.2-13
## [47] Matrix_1.5-4 ggbeeswarm_0.7.1
## [49] fansi_1.0.4 abind_1.4-5
## [51] R.methodsS3_1.8.2 terra_1.7-23
## [53] lifecycle_1.0.3 yaml_2.3.7
## [55] edgeR_3.41.6 carData_3.0-5
## [57] rhdf5_2.43.4 blob_1.2.4
## [59] grid_4.3.0 promises_1.2.0.1
## [61] dqrng_0.3.0 crayon_1.5.2
## [63] shinydashboard_0.7.2 lattice_0.21-8
## [65] cowplot_1.1.1 beachmat_2.15.2
## [67] annotate_1.77.0 KEGGREST_1.39.0
## [69] magick_2.7.4 pillar_1.9.0
## [71] knitr_1.42 rjson_0.2.21
## [73] boot_1.3-28.1 fpc_2.2-10
## [75] codetools_0.2-19 glue_1.6.2
## [77] FCPS_1.3.1 data.table_1.14.8
## [79] vctrs_0.6.1 png_0.1-8
## [81] gtable_0.3.3 kernlab_0.9-32
## [83] cachem_1.0.7 xfun_0.38
## [85] princurve_2.1.6 mime_0.12
## [87] DropletUtils_1.19.3 coop_0.6-3
## [89] pheatmap_1.0.12 ellipsis_0.3.2
## [91] nlme_3.1-162 bit64_4.0.5
## [93] RcppAnnoy_0.0.20 rprojroot_2.0.3
## [95] bslib_0.4.2 irlba_2.3.5.1
## [97] svgPanZoom_0.3.4 vipor_0.4.5
## [99] DBI_1.1.3 colorspace_2.1-0
## [101] nnet_7.3-18 raster_3.6-20
## [103] mnormt_2.1.1 tidyselect_1.2.0
## [105] bit_4.0.5 compiler_4.3.0
## [107] BiocNeighbors_1.17.1 desc_1.4.2
## [109] DelayedArray_0.25.0 bookdown_0.33
## [111] scales_1.2.1 DEoptimR_1.0-12
## [113] psych_2.3.3 tiff_0.1-11
## [115] stringr_1.5.0 SpatialExperiment_1.9.5
## [117] digest_0.6.31 goftest_1.2-3
## [119] fftwtools_0.9-11 spatstat.utils_3.0-2
## [121] minqa_1.2.5 rmarkdown_2.21
## [123] XVector_0.39.0 htmltools_0.5.5
## [125] pkgconfig_2.0.3 jpeg_0.1-10
## [127] lme4_1.1-32 sparseMatrixStats_1.11.1
## [129] highr_0.10 fastmap_1.1.1
## [131] rlang_1.1.0 htmlwidgets_1.6.2
## [133] shiny_1.7.4 DelayedMatrixStats_1.21.0
## [135] farver_2.1.1 jquerylib_0.1.4
## [137] jsonlite_1.8.4 mclust_6.0.0
## [139] R.oo_1.25.0 BiocSingular_1.15.0
## [141] RCurl_1.98-1.12 magrittr_2.0.3
## [143] modeltools_0.2-23 GenomeInfoDbData_1.2.10
## [145] ggplotify_0.1.0 Rhdf5lib_1.21.0
## [147] munsell_0.5.0 Rcpp_1.0.10
## [149] viridis_0.6.2 stringi_1.7.12
## [151] zlibbioc_1.45.0 MASS_7.3-58.4
## [153] flexmix_2.3-19 plyr_1.8.8
## [155] parallel_4.3.0 ggrepel_0.9.3
## [157] deldir_1.0-6 Biostrings_2.67.2
## [159] splines_4.3.0 tensor_1.5
## [161] locfit_1.5-9.7 fastcluster_1.2.3
## [163] spatstat.geom_3.1-0 ggsignif_0.6.4
## [165] reshape2_1.4.4 ScaledMatrix_1.7.0
## [167] XML_3.99-0.14 evaluate_0.20
## [169] BiocManager_1.30.20 nloptr_2.0.3
## [171] tweenr_2.0.2 httpuv_1.6.9
## [173] tidyr_1.3.0 purrr_1.0.1
## [175] polyclip_1.10-4 ggforce_0.4.1
## [177] rsvd_1.0.5 broom_1.0.4
## [179] xtable_1.8-4 rstatix_0.7.2
## [181] later_1.3.0 viridisLite_0.4.1
## [183] class_7.3-21 ragg_1.2.5
## [185] tibble_3.2.1 lmerTest_3.1-3
## [187] AnnotationDbi_1.61.2 memoise_2.0.1
## [189] beeswarm_0.4.0 cluster_2.1.4
## [191] concaveman_1.1.0