An Introduction to Statial
Source:vignettes/An_introduction_to_Statial.Rmd
An_introduction_to_Statial.Rmd
Farhan Ameen, Alex Qin, Nick Robertson, Sourish Iyengar, Shila Ghazanfar, Ellis Patrick\(^{1,2,3}\).
\(^1\) Westmead Institute for
Medical Research, University of Sydney, Australia
\(^2\) Sydney Precision Data Science
Centre, University of Sydney, Australia
\(^3\) School of Mathematics and
Statistics, University of Sydney, Australia
contact: ellis.patrick@sydney.edu.au
Overview
There are over 37 trillion cells in the human body, each taking up different forms and functions. The behaviour of these cells can be described by canonical characteristics, but their functions can also dynamically change based on their environmental context, leading to cells with diverse states. Understanding changes in cell state related to their spatial context in the tissue microenvironment is key to understanding how spatial interactions between cells can contributes to human disease. State-of-the-art technologies such as PhenoCycler, IMC, CosMx, Xenium, MERFISH and many others have made it possible to deeply phenotype characteristics of cells in their native environment. This has created the exciting opportunity to identify spatially related changes in cell state in a high-thoughput manner.
Description
Statial is a Bioconductor package which contains a suite of complementary approaches for identifying changes in cell state and how these changes are associated with cell type localisation. This workshop will introduce new functionality in the Statial package which can:
- Model spatial relationships between cells in the context of hierarchical cell lineage structures
- Uncover changes in marker expression associated with cell proximities
- Identify changes in cell state between distinct tissue environments
Pre-requisites
It is expected that students will have:
- Basic knowledge of R syntax
- Familiarity with SingleCellExperiment and/or SpatialExperiment objects
- This workshop will not provide an in-depth description of cell-resolution spatial omics technologies
Participation
While it will be possible for participants to run code as we go through the demonstration, given time constraints, I would encourage them to focus their attention into critiquing when and why modelling the spatial relationships between cells in these ways is appropriate. Questions are welcome both within the workshop and if students choose to work through the workshop independently after the demonstration.
R / Bioconductor packages used
While this workshop will focus on the functionality of Statial, it will tangentially touch on other Bioconductor packages we have developed for these technologies such as spicyR, lisaClust and ClassifyR.



Time outline
An example for a 45-minute workshop:
The expected timing of the workshop:
| Activity | Time |
|---|---|
| Introduction | 5m |
| Discrete cell states | 10m |
| Continuous cell states | 10m |
| Tissue microenvironments | 5m |
| Classification | 5m |
Workshop
Installation
if (!requireNamespace("BiocManager", quietly = TRUE)) {
install.packages("BiocManager")
}
BiocManager::install(c("Statial", "spicyR", "lisaClust", "ClassifyR", "ggplot2", "SpatialExperiment", "dplyr",
"tidyr", "ggsurvfit", "scater"))Load packages
library(StatialBioc2023)
library(Statial)
library(spicyR)
library(lisaClust)
library(ClassifyR)
library(ggplot2)
library(SpatialExperiment)
library(dplyr)
library(tidyr)
library(ggsurvfit)
library(scater)
theme_set(theme_classic())
nCores <- 1 # Feel free to parallelise things if you have the cores to spare.The definitions of cell types and cell states are somewhat ambiguous. We will purposefully skirt the debate of what is a cell type vs cell state. Instead, in this workshop I would ask participants to associate cell state terminology to simply mean a varying phenotype (state) of a large cluster of similar cells (cell type). In this workshop we will examine two analytically distinct changes in cell state:
-
A discrete change in state. Cell types (clusters of cells)
are further clustered into sub-clusters. These finer-resolution
phenotypes of the cell type are labelled as cell states.
- A continuous change in state. The state of a cell type is defined by variation in abundance of a gene or protein.
The data
To illustrate the functionality of Statial we will use a multiplexed ion beam imaging by time-of-flight (MIBI-TOF) dataset profiling tissue from triple-negative breast cancer patients\(^1\). This dataset simultaneously quantifies in situ expression of 36 proteins in 34 immune rich patients. Note: The data contains some “uninformative” probes and the original cohort included 41 patients.
The data is stored in a SpatialExperiment object called
kerenSPE. We can load the data and view some basic
characteristics.
data("kerenSPE", package = "StatialBioc2023")
# Filter out samples with few immune cells and those without survival information.
kerenSPE <- kerenSPE[,kerenSPE$tumour_type!="cold" & !is.na(kerenSPE$`Survival_days_capped*`)]
kerenSPE
#> class: SpatialExperiment
#> dim: 48 170171
#> metadata(0):
#> assays(1): intensities
#> rownames(48): Na Si ... Ta Au
#> rowData names(0):
#> colnames(170171): 1 2 ... 197677 197678
#> colData names(42): x y ... Censored sample_id
#> reducedDimNames(2): spatialCoords UMAP
#> mainExpName: NULL
#> altExpNames(0):
#> spatialCoords names(2) : x y
#> imgData names(1): sample_idAs our data is stored in a SpatialExperiment, with the
spatialCoords also stored as a reducedDim, we
can use scater to visualise our data in a lower dimensional
embedding and look for image or cluster differences.
# Perform dimension reduction using UMAP.
# I have already run this and saved it in kerenSPE so that you can save time.
#
# set.seed(51773)
# kerenSPE <- scater::runUMAP(kerenSPE, exprs_values = "intensities", name = "UMAP")
# UMAP by imageID.
scater::plotReducedDim(kerenSPE, dimred = "UMAP", colour_by = "cellType")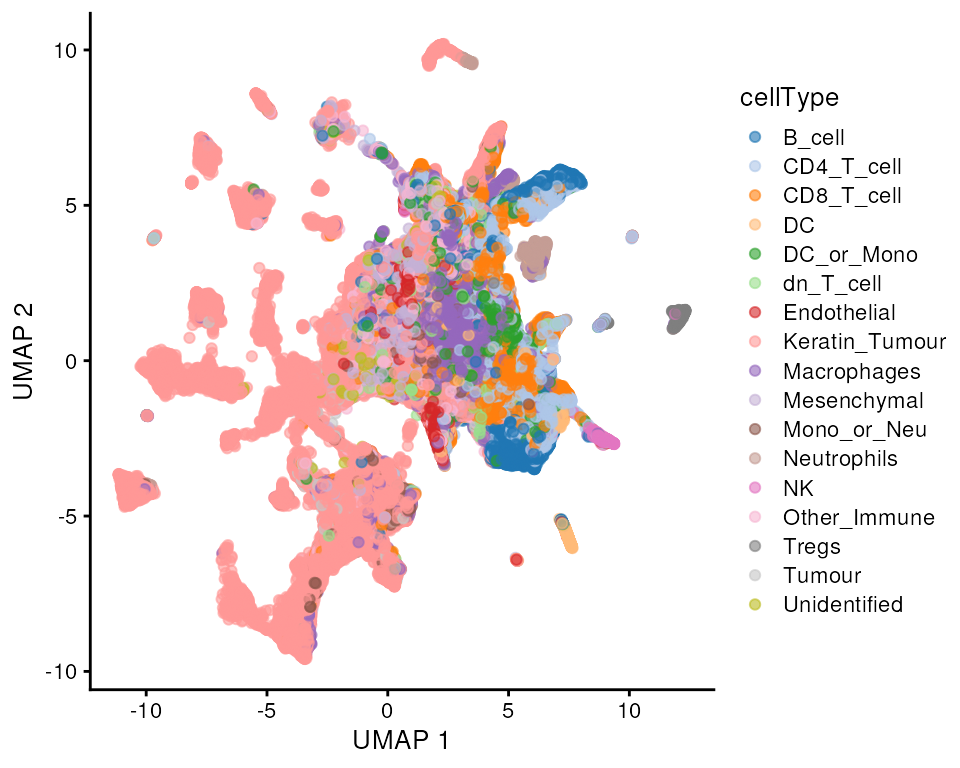
Question
- What does this UMAP tell us?
- What are some observations we could make if we coloured by
imageID?
Identifying discrete changes in cell state with Kontextual
Cells states can be modelled as subclusters of a broader parent cell population. These subclusters, or states, are typically identified via a hierarchical clustering strategy. By framing cell states as discrete clusters, we are able to explore relationships as follows - cell type A has two states, with state 2 being closer to cell type B.
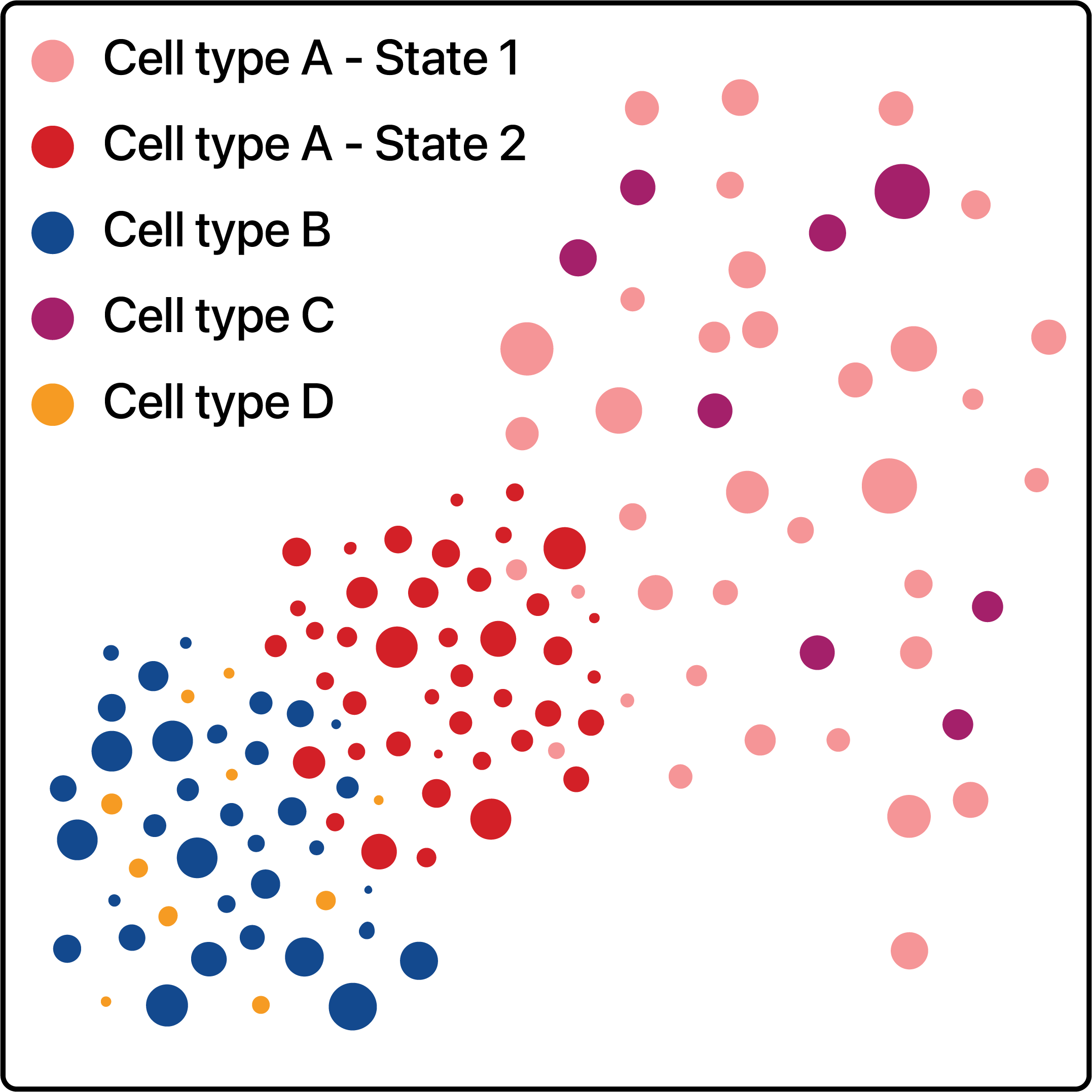
Here we introduce Kontextual. Kontextual models spatial relationships between cells in the context of hierarchical cell lineage structures. By assessing spatial relationships between pairs of cells in the context of other related cell types, Kontextual provides robust quantification of cell type relationships which are invariant to changes in tissue structure.
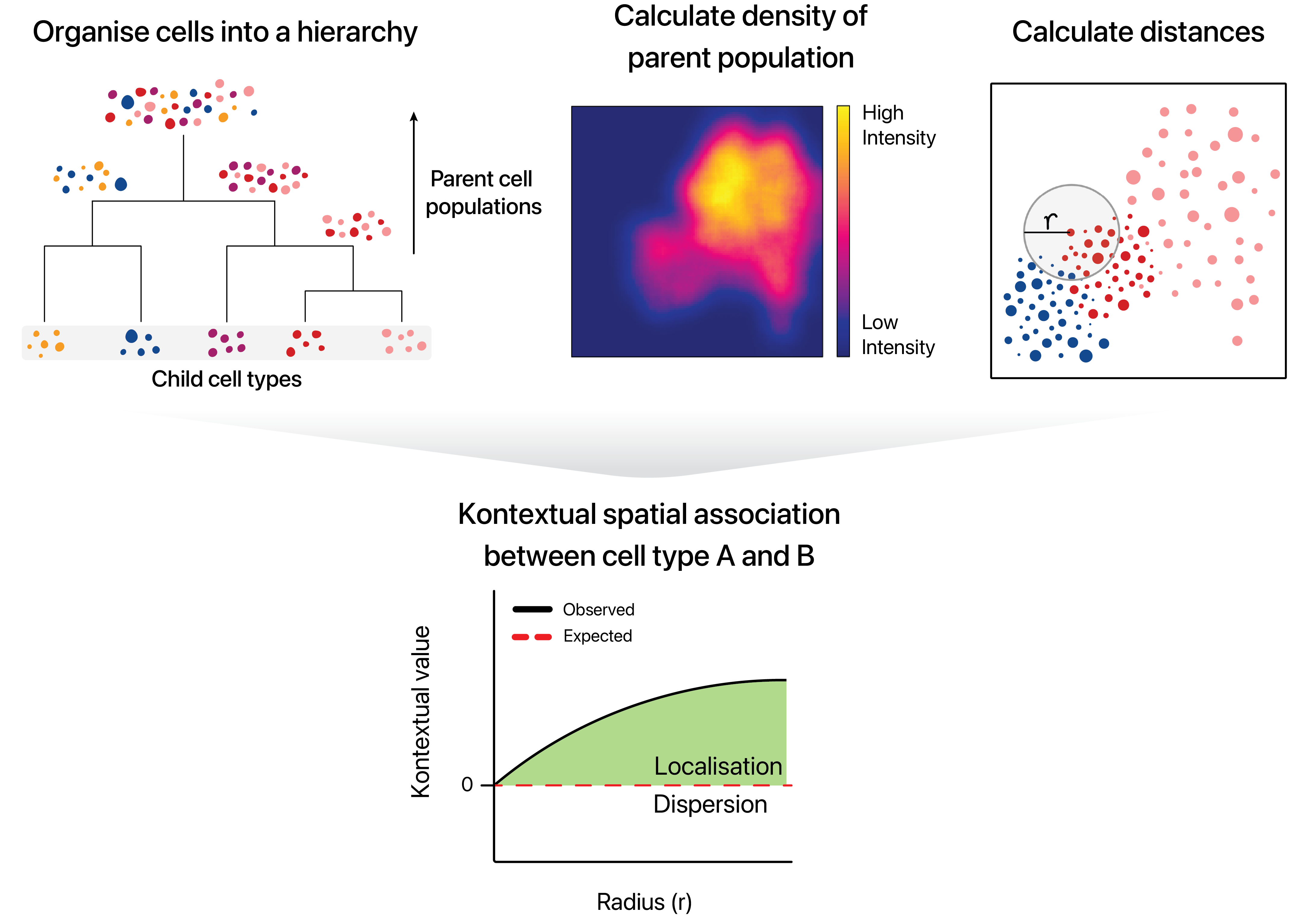
For the purposes of using Kontextual we treat cell
states as identified clusters of cells, where larger clusters represent
a “parent” cell population, and finer sub-clusters representing a
“child” cell population. For example a CD4+ T cell may be considered a
child to a larger parent population of T cells. Kontextual
thus aims to quantify how the localisation patterns of a child
population of cells deviate from the spatial behaviour of their parent
population, and how that influences the localisation between the child
cell state and another cell state.
Cell type hierarchy
A key input for Kontextual is an annotation of cell type hierarchies. We will need these to organise all the cells present into cell state populations or clusters, e.g. all the different B cell types are put in a vector called bcells.
To make our lives easier, we will start by defining these here. I’m happy to talk about how we use our bioconductor package treekoR to define these hierarchies in a data driven way.
# Set up cell populations
tumour <- c("Keratin_Tumour", "Tumour")
bcells <- c("B_cell")
tcells <- c("dn_T_cell", "CD4_T_cell", "CD8_T_cell", "Tregs")
myeloid <- c("Dc_or_Mono", "DC", "Mono_or_Neu", "Macrophages", "Other_Immune", "Neutrophils")
endothelial <- c("Endothelial")
mesenchymal <- c("Mesenchymal")
tissue <- c(endothelial, mesenchymal)
immune <- c(bcells, tcells, myeloid, "NK")
all <- c(tumour, tissue, immune, "Unidentified")Discrete cell state changes within a single image
Here we examine an image highlighted in the Keren et al. 2018 manuscript where the relationship between two cell types depends on a parent cell population. In image 6 of the Keren et al. dataset, we can see that p53+ tumour cells and immune cells are dispersed. However when the behaviour of p53+ tumour cells are placed in the context of the spatial behaviour of its broader parent population tumour cells, p53+ tumour cells and immune would appear localised.
# Lets define a new cell type vector
kerenSPE$cellTypeNew <- kerenSPE$cellType
# Select for all cells that express higher than baseline level of p53
p53Pos = assay(kerenSPE)["p53",] > -0.300460
# Find p53+ tumour cells
kerenSPE$cellTypeNew[kerenSPE$cellType %in% tumour] <- "Tumour"
kerenSPE$cellTypeNew[p53Pos & kerenSPE$cellType %in% tumour] <- "p53_Tumour"
#Group all immune cells under the name "Immune"
kerenSPE$cellTypeNew[kerenSPE$cellType %in% immune] <- "Immune"
# Plot image 6
kerenSPE |>
colData() |>
as.data.frame() |>
filter(imageID == "6") |>
filter(cellTypeNew %in% c("Immune", "Tumour", "p53_Tumour")) |>
arrange(cellTypeNew) |>
ggplot(aes(x = x, y = y, color = cellTypeNew)) +
geom_point(size = 1) +
scale_colour_manual(values = c("#505050", "#64BC46","#D6D6D6")) + guides(colour = guide_legend(title = "Cell types", override.aes = list(size=3)))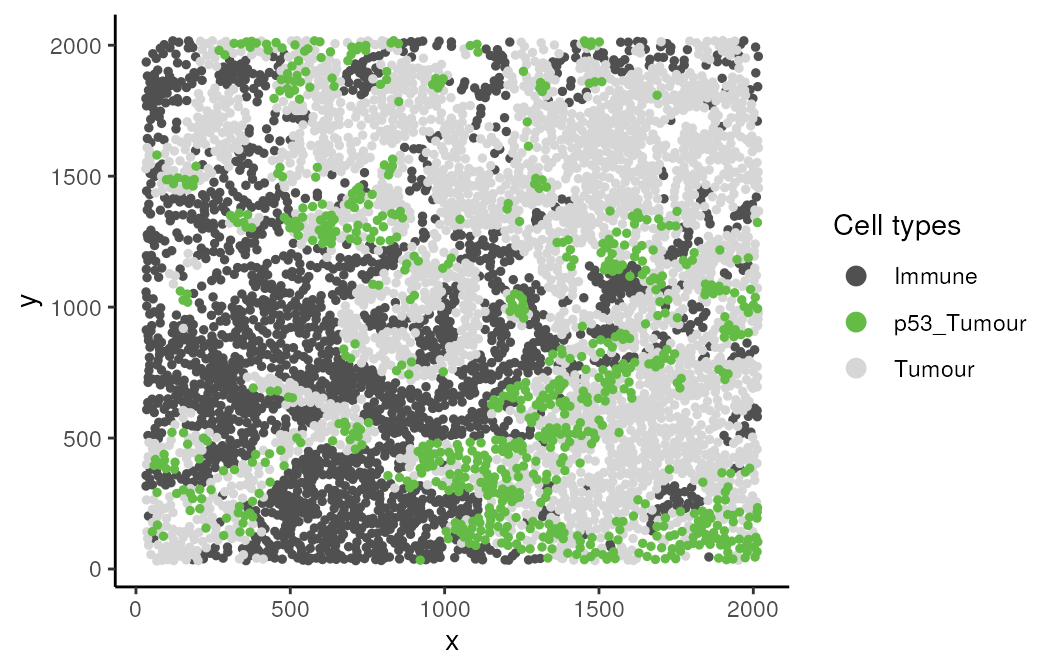
The Kontextual function accepts a
SingleCellExperiment object, or a single image, or list of
images from a SingleCellExperiment object, this gets passed
into the cells argument. The two cell types which will be
evaluated are specified in the to and from
arguments. A parent population must also be specified in the
parent argument, note the parent cell population must
include the to cell type. The argument r will
specify the radius which the cell relationship will be evaluated on.
Kontextual supports parallel processing, the number of
cores can be specified using the cores argument.
Kontextual can take a single value or multiple values for
each argument and will test all combinations of the arguments
specified.
We can calculate these relationships for a single radius.
p53_Kontextual <- Kontextual(
cells = kerenSPE,
image = 6,
r = 50,
from = "p53_Tumour",
to = "Immune",
parent = c("p53", "Tumour"),
cellType = "cellTypeNew"
)
p53_Kontextual
#> imageID test original kontextual r weightQuantile inhom edge
#> 1 6 p53_Tumour__Immune -21.42647 2.690005 50 0.8 TRUE FALSE
#> includeZeroCells window window.length
#> 1 TRUE convex NAThe kontextCurve calculates the L-function value and
Kontextual values over a range of radii. While kontextPlot
plots these values. If the points lie above the red line (expected
pattern) then localisation is indicated for that radius, if the points
lie below the red line then dispersion is indicated. As seen in the
following plot Kontextual is able to correctly identify localisation
between p53+ tumour cells and immune cells in the example image for a
certain range of radii. The original L-function is not able to identify
localisation at any value of radii.
curves <- kontextCurve(
cells = kerenSPE,
image = "6",
from = "p53_Tumour",
to = "Immune",
parent = c("p53+Tumour", "Tumour"),
rs = seq(10, 510, 100),
cellType = "cellTypeNew",
cores = nCores
)
kontextPlot(curves)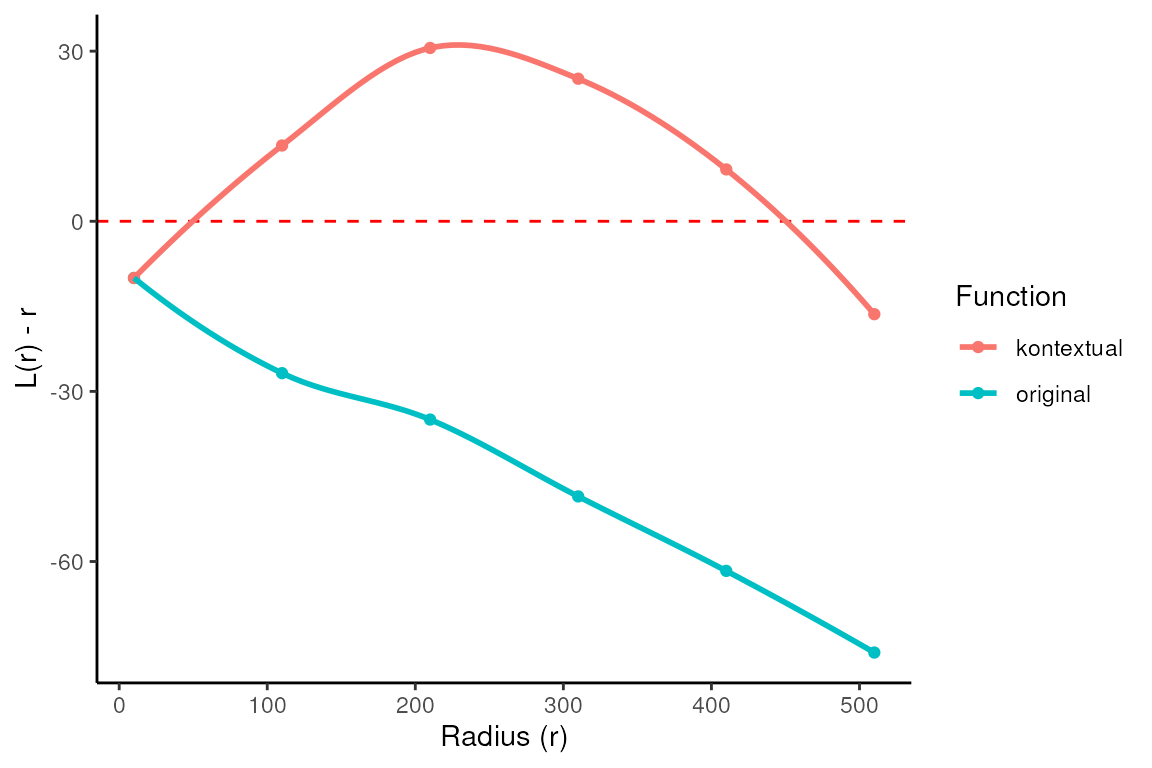
Alternatively all pairwise cell relationships and their corresponding
parents in the dataset can be tested. A data frame with all pairwise
combinations can be creating using the parentCombinations
function. This function takes in a vector of all the cells, as well as
all the parent vectors set up earlier. As shown below the output is a
data frame specifying the to, from, and
parent arguments for Kontextual.
# Get all relationships between cell types and their parents
parentDf <- parentCombinations(
all = all,
tumour,
bcells,
tcells,
myeloid,
endothelial,
mesenchymal,
tissue,
immune
)Discrete cell state changes across all images
Rather than specifying to, from, and
parent in Kontextual, the output from
parentCombinations can be input into
Kontextual using the parentDf argument, to
examine all pairwise relationships in the dataset. This chunk will take
a signficant amount of time to run (~20 minutes), for demonstration the
results have been saved and are loaded in.
# Running Kontextual on all relationships across all images.
kerenKontextual <- Kontextual(
cells = kerenSPE,
parentDf = parentDf,
r = 50,
cores = nCores
)
data("kerenKontextual", package = "StatialBioc2023")
bigDiff <- (kerenKontextual$original - kerenKontextual$kontextual)
head(kerenKontextual[order(bigDiff),], 10)
#> imageID test original kontextual r
#> 12252 18 dn_T_cell__Mesenchymal__tcells 42.540392 291.9508 50
#> 14929 23 Tumour__dn_T_cell__tumour 96.667594 325.5462 50
#> 14846 5 Tumour__Endothelial__tumour -22.329210 181.6454 50
#> 14968 32 Tumour__CD4_T_cell__tumour 37.890443 226.8310 50
#> 14902 32 Tumour__B_cell__tumour 71.070831 239.4044 50
#> 15193 23 Tumour__Other_Immune__tumour 102.570063 265.9990 50
#> 6879 28 Tregs__Keratin_Tumour__immune -9.816640 145.2949 50
#> 4767 28 Mono_or_Neu__Keratin_Tumour__immune -1.959462 150.8993 50
#> 12687 28 Tregs__Keratin_Tumour__tcells -9.816640 136.9530 50
#> 15143 5 Tumour__Mono_or_Neu__tumour -8.341033 126.4892 50
#> weightQuantile inhom edge includeZeroCells window window.length
#> 12252 0.8 TRUE FALSE TRUE convex NA
#> 14929 0.8 TRUE FALSE TRUE convex NA
#> 14846 0.8 TRUE FALSE TRUE convex NA
#> 14968 0.8 TRUE FALSE TRUE convex NA
#> 14902 0.8 TRUE FALSE TRUE convex NA
#> 15193 0.8 TRUE FALSE TRUE convex NA
#> 6879 0.8 TRUE FALSE TRUE convex NA
#> 4767 0.8 TRUE FALSE TRUE convex NA
#> 12687 0.8 TRUE FALSE TRUE convex NA
#> 15143 0.8 TRUE FALSE TRUE convex NAAssociate discrete state changes with survival outcomes
To examine whether the features obtained from Statial
are associated with patient outcomes or groupings, we can use the
colTest function from SpicyR. To understand if
survival outcomes differ significantly between 2 patient groups, specify
type = "survival" in colTest. Here we examine
which features are most associated with patient survival using the
Kontextual values as an example. To do so, survival data is extracted
from kerenSPE and converted into the survival object
kerenSurv.
# Extracting survival data
survData = kerenSPE |>
colData() |>
data.frame() |>
select(imageID, Survival_days_capped., Censored) |>
unique()
# Creating survival vector
kerenSurv = Surv(survData$Survival_days_capped, survData$Censored)
names(kerenSurv) = survData$imageIDIn addition to this, the Kontextual results must be converted from a
data.frame to a wide matrix, this can be done
using prepMatrix. Note, to extract the original L-function
values, specify column = "original" in
prepMatrix.
# Converting Kontextual result into data matrix
kontextMat = prepMatrix(kerenKontextual)
# Ensuring rownames of kontextMat match up with rownames of the survival vector
kontextMat = kontextMat[names(kerenSurv), ]
# Replace NAs with 0
kontextMat[is.na(kontextMat )] <- 0Finally, both the Kontextual matrix and survival object are passed
into colTest, with type = "survival" to obtain
the survival results.
# Running survival analysis
survivalResults = spicyR::colTest(kontextMat, kerenSurv, type = "survival")
head(survivalResults)
#> coef se.coef pval adjPval
#> Mesenchymal__Macrophages__tissue -0.130 0.0340 0.00017 0.069
#> CD4_T_cell__CD8_T_cell__tcells 0.260 0.0790 0.00094 0.150
#> Endothelial__Mono_or_Neu__tissue -0.035 0.0110 0.00110 0.150
#> Mesenchymal__Other_Immune__tissue 0.068 0.0220 0.00230 0.200
#> Tumour__CD4_T_cell__tumour 0.011 0.0036 0.00320 0.200
#> dn_T_cell__CD8_T_cell__immune 0.098 0.0330 0.00340 0.200
#> cluster
#> Mesenchymal__Macrophages__tissue Mesenchymal__Macrophages__tissue
#> CD4_T_cell__CD8_T_cell__tcells CD4_T_cell__CD8_T_cell__tcells
#> Endothelial__Mono_or_Neu__tissue Endothelial__Mono_or_Neu__tissue
#> Mesenchymal__Other_Immune__tissue Mesenchymal__Other_Immune__tissue
#> Tumour__CD4_T_cell__tumour Tumour__CD4_T_cell__tumour
#> dn_T_cell__CD8_T_cell__immune dn_T_cell__CD8_T_cell__immuneAs we can see from the results
Mesenchymal__Macrophages__tissue is the most significant
pairwise relationship which contributes to patient survival. That is the
relationship between Mesenchymal cells and macrophage cells, relative to
the parent population of all tissue cells. We can see that there is a
negative coefficient associated with this relationship, which tells us a
decrease in localisation of Mesenchymal and Macrophages leads to poorer
survival outcomes for patients.
The association between Mesenchymal__Macrophages__tissue
and survival can also be visualised on a Kaplan-Meier curve. We must
first extract the Kontextual values of this relationship across all
images. Next we determine if Mesenchymal and Macrophages are relatively
attracted or avoiding in each image, by comparing the Kontextual value
in each image to the median Kontextual value. Finally we plot the
Kaplan-Meier curve using the ggsurvfit package.
As shown below, when Mesenchymal and Macrophages are relatively more dispersed to one another, patients tend to have worse survival outcomes.
# Selecting most significant relationship
survRelationship = kontextMat[["Mesenchymal__Macrophages__tissue"]]
survRelationship = ifelse(survRelationship > median(survRelationship), "Localised", "Dispersed")
# Plotting Kaplan-Meier curve
survfit2(kerenSurv ~ survRelationship) |>
ggsurvfit() +
add_pvalue() +
ggtitle("Mesenchymal__Macrophages__tissue")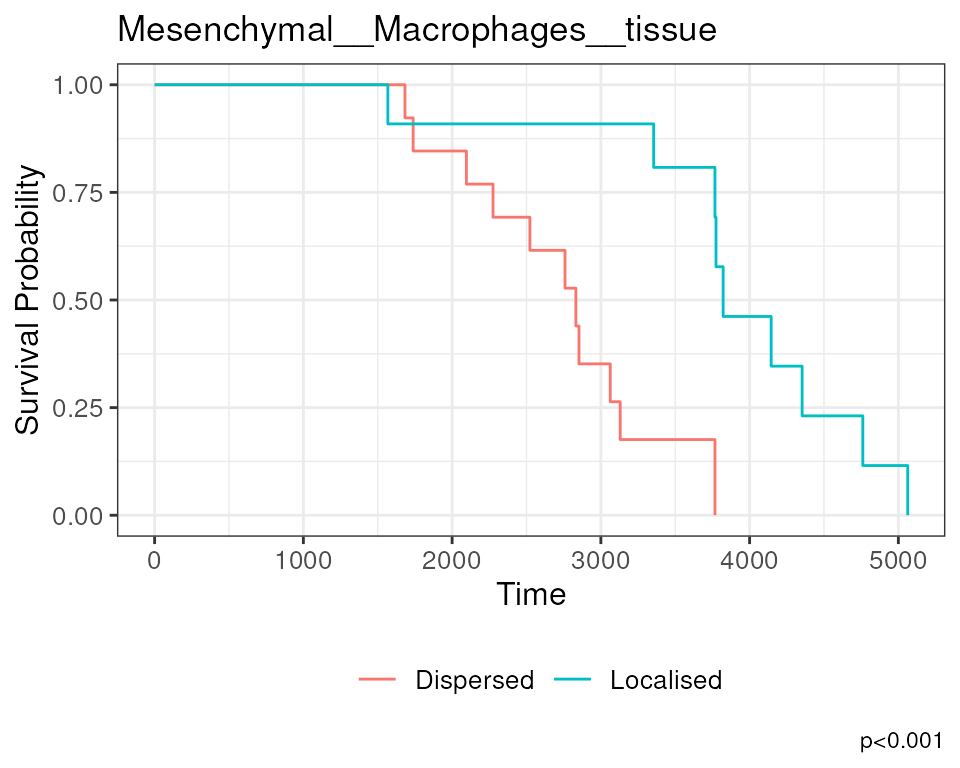
Identifying continuous changes in cell state
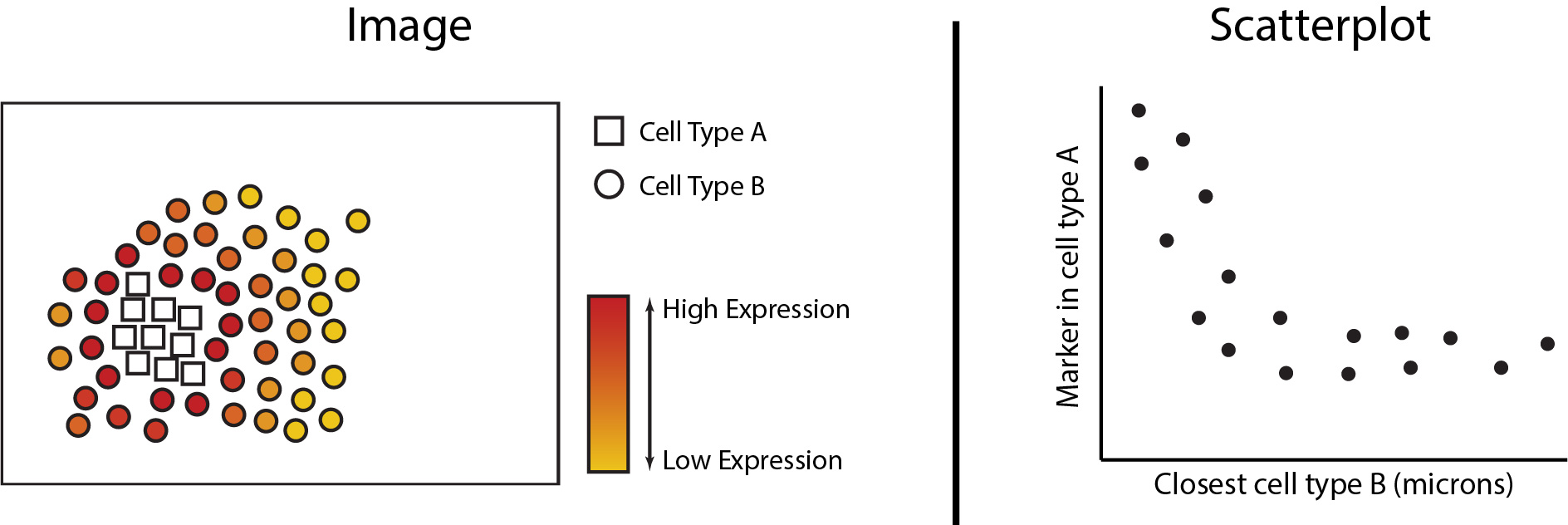
Changes in cell states can be analytically framed as the change in abundance of a gene or protein within a particular cell type. We can analytically determine whether continuous changes occur to a cell’s state as changes occur in its spatial proximity to another cell type. In the figures below we see the expression of a marker increased in cell type A as it grows closer in spatial proximity to cell type B. This can then be quantified with a scatterplot to determine statistical significance. In the next section of this workshop, we will be exploring the analytical functionalities of Statial which can uncover these continuous changes in cell state.
Continuous cell state changes within a single image.
The first step in analysing these changes is to calculate the spatial
proximity (getDistances) and abundance
(getAbundances) of each cell to every cell type. These
values will then be stored in the reducedDims slot of the
SpatialExperiment object under the names
distances and abundances respectively.
kerenSPE <- getDistances(kerenSPE,
maxDist = 200)
kerenSPE <- getAbundances(kerenSPE,
r = 50)First, let’s examine the same effect observed earlier with Kontextual. To avoid redefining cell types we’ll examine the distance between p53-positive tumour cells and macrophages in the context of total keratin/tumour cells for image 6.
Statial provides two main functions to assess this relationship -
calcStateChanges and plotStateChanges. We can
use calcStateChanges to examine the relationship between 2
cell types for 1 marker in a specific image. Similar to
Kontextual, we can specify the two cell types with the
to and from arguments, and the marker of
interest with the marker argument. We can appreciate that
the fdr statistic for this relationship is significant, and
with a negative coef, or coefficient value, indicating that
the expression of p53 in keratin/tumour cells decreases as distance from
macrophages increases.
stateChanges <- calcStateChanges(
cells = kerenSPE,
type = "distances",
image = "6",
from = "Keratin_Tumour",
to = "Macrophages",
marker = "p53")
stateChanges
#> imageID primaryCellType otherCellType marker coef tval
#> 1 6 Keratin_Tumour Macrophages p53 -0.001402178 -7.010113
#> pval fdr
#> 1 2.868257e-12 2.868257e-12Statial provides a convenient function for visualising this
relationship - plotStateChanges. Similar to
Kontextual and calcStateChanges, we can
specify the cell types to be evaluated with the to and
from arguments and the marker of interest with
marker.
Through this analysis, we can observe that keratin/tumour cells closer to a group of macrophages tend to have higher expression of p53, as observed in the first graph. This relationship is quantified with the second graph, showing an overall decrease of p53 expression in keratin/tumour cells as distance to macrophages increase.
These results allow us to essentially arrive at the same result as Kontextual, which calculated a localisation between p53+ keratin/tumour cells and macrophages in the wider context of keratin/tumour cells.
p <- plotStateChanges(
cells = kerenSPE,
type = "distances",
image = "6",
from = "Keratin_Tumour",
to = "Macrophages",
marker = "p53",
size = 1,
shape = 19,
interactive = FALSE,
plotModelFit = FALSE,
method = "lm")
p$image +
labs(y = "p53 expression in Keratin_Tumour",
x = "Distance of Keratin_Tumour to Macrophages")
#> Warning: The dot-dot notation (`..density..`) was deprecated in ggplot2 3.4.0.
#> ℹ Please use `after_stat(density)` instead.
#> ℹ The deprecated feature was likely used in the Statial package.
#> Please report the issue at <https://github.com/SydneyBioX/Statial/issues>.
#> This warning is displayed once every 8 hours.
#> Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
#> generated.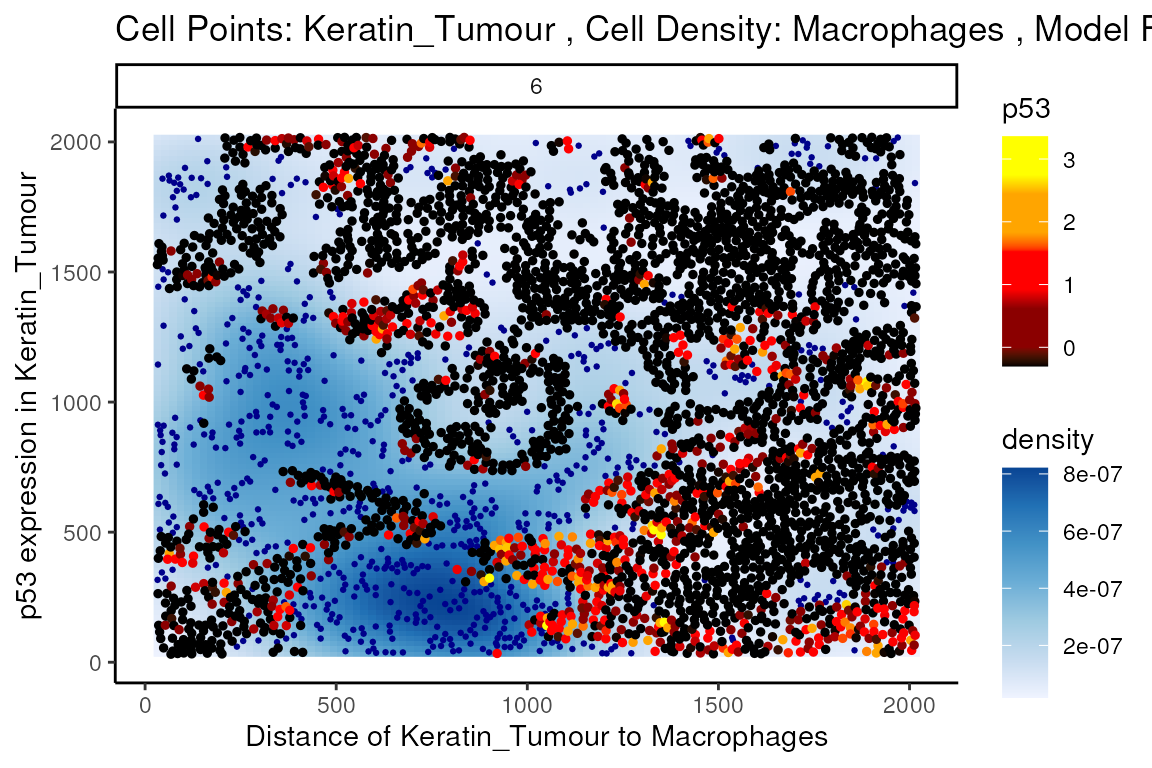
p$scatter
#> `geom_smooth()` using formula = 'y ~ x'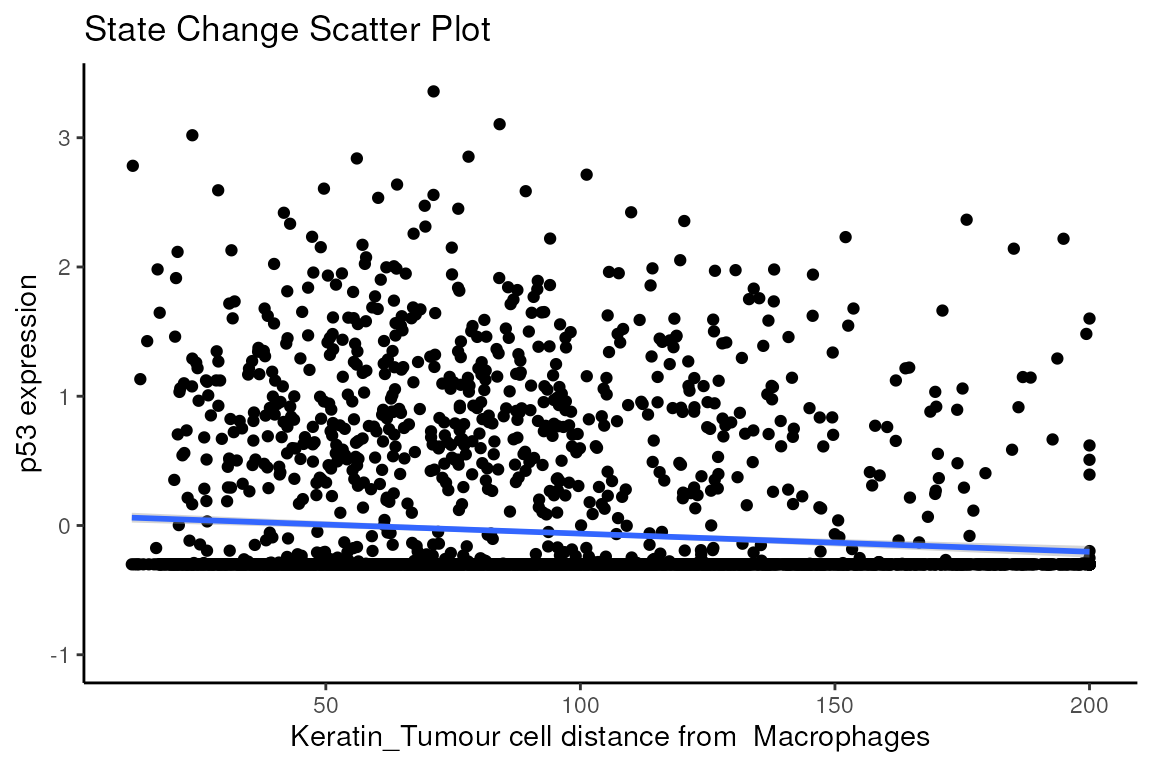
Question
- What information does this form of analysis provide that Kontextual does not?
- Is this observation of localisation consistent across images?
- Can you find an interaction where the coefficient is positive?
i.e. marker expression in the
tocell type rises as distances increases from thefromcell type.
Continuous cell state changes across all images.
Beyond looking at single cell-to-cell interactions for a single
image, we can also look at all interactions across all images. The
calcStateChanges function provided by Statial can be
expanded for this exact purpose - by not specifying cell types, a
marker, or an image, calcStateChanges will examine the most
significant correlations between distance and marker expression across
the entire dataset. Here, we’ve calculated all state changes across all
images in case you would like to have a play, but first we’ll be taking
a closer examination at the most significant interactions found within
image 6 of the Keren et al. dataset.
stateChanges <- calcStateChanges(
cells = kerenSPE,
type = "distances",
minCells = 100)
stateChanges |>
filter(imageID == 6) |>
head(n = 10)
#> imageID primaryCellType otherCellType marker coef tval
#> 1 6 Keratin_Tumour Unidentified Na 0.004218419 25.03039
#> 2 6 Keratin_Tumour Macrophages HLA_Class_1 -0.003823497 -24.69629
#> 3 6 Keratin_Tumour CD4_T_cell HLA_Class_1 -0.003582774 -23.87797
#> 4 6 Keratin_Tumour Unidentified Beta.catenin 0.005893120 23.41953
#> 5 6 Keratin_Tumour CD8_T_cell HLA_Class_1 -0.003154544 -23.13804
#> 6 6 Keratin_Tumour DC_or_Mono HLA_Class_1 -0.003353834 -22.98944
#> 7 6 Keratin_Tumour dn_T_cell HLA_Class_1 -0.003123446 -22.63197
#> 8 6 Keratin_Tumour Tumour HLA_Class_1 0.003684079 21.94265
#> 9 6 Keratin_Tumour CD4_T_cell Fe -0.003457338 -21.43550
#> 10 6 Keratin_Tumour CD4_T_cell phospho.S6 -0.002892457 -20.50767
#> pval fdr
#> 1 6.971648e-127 3.397226e-123
#> 2 7.814253e-124 3.427038e-120
#> 3 1.745242e-116 5.669614e-113
#> 4 1.917245e-112 5.798841e-109
#> 5 5.444541e-110 1.516046e-106
#> 6 1.053130e-108 2.842235e-105
#> 7 1.237988e-105 3.016305e-102
#> 8 8.188258e-100 1.710030e-96
#> 9 1.287478e-95 2.352664e-92
#> 10 3.928912e-88 5.890849e-85In image 6, the majority of the top 10 most significant interactions occur between keratin/tumour cells and an immune population, and many of these interactions appear to involve the HLA class I ligand.
We can examine some of these interactions further with the
plotStateChanges function. Taking a closer examination of
the relationship between macrophages and keratin/tumour HLA class I
expression, the plot below shows us a clear visual correlation - as
macrophage density increases, keratin/tumour cells increase their
expression HLA class I.
Biologically, HLA Class I is a ligand which exists on all nucleated cells, tasked with presenting internal cell antigens for recognition by the immune system, marking aberrant cells for destruction by either CD8+ T cells or NK cells.
p <- plotStateChanges(
cells = kerenSPE,
type = "distances",
image = "6",
from = "Keratin_Tumour",
to = "Macrophages",
marker = "HLA_Class_1",
size = 1,
shape = 19,
interactive = FALSE,
plotModelFit = FALSE,
method = "lm")
p$image +
labs(y = "HLA_Class_1 expression in Keratin_Tumour",
x = "Distance of Keratin_Tumour to Macrophages")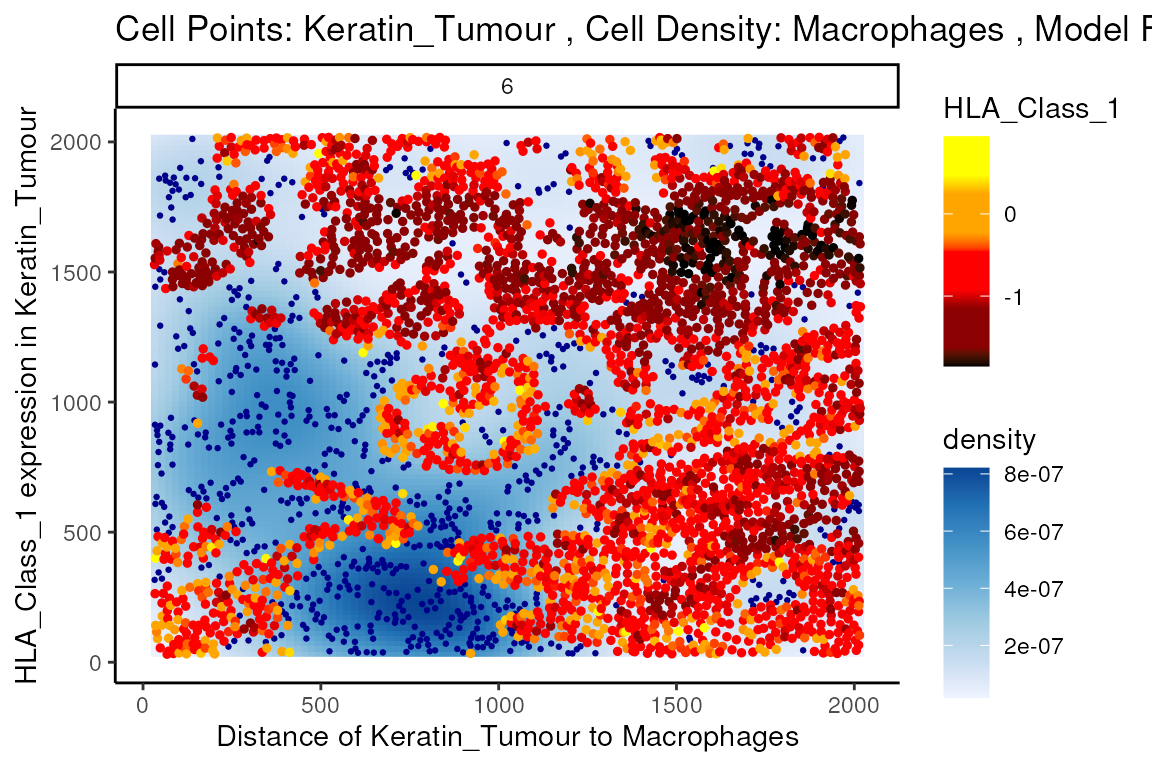
p$scatter
#> `geom_smooth()` using formula = 'y ~ x'
#> Warning: Removed 1359 rows containing non-finite values
#> (`stat_smooth()`).
#> Warning: Removed 1359 rows containing missing values (`geom_point()`).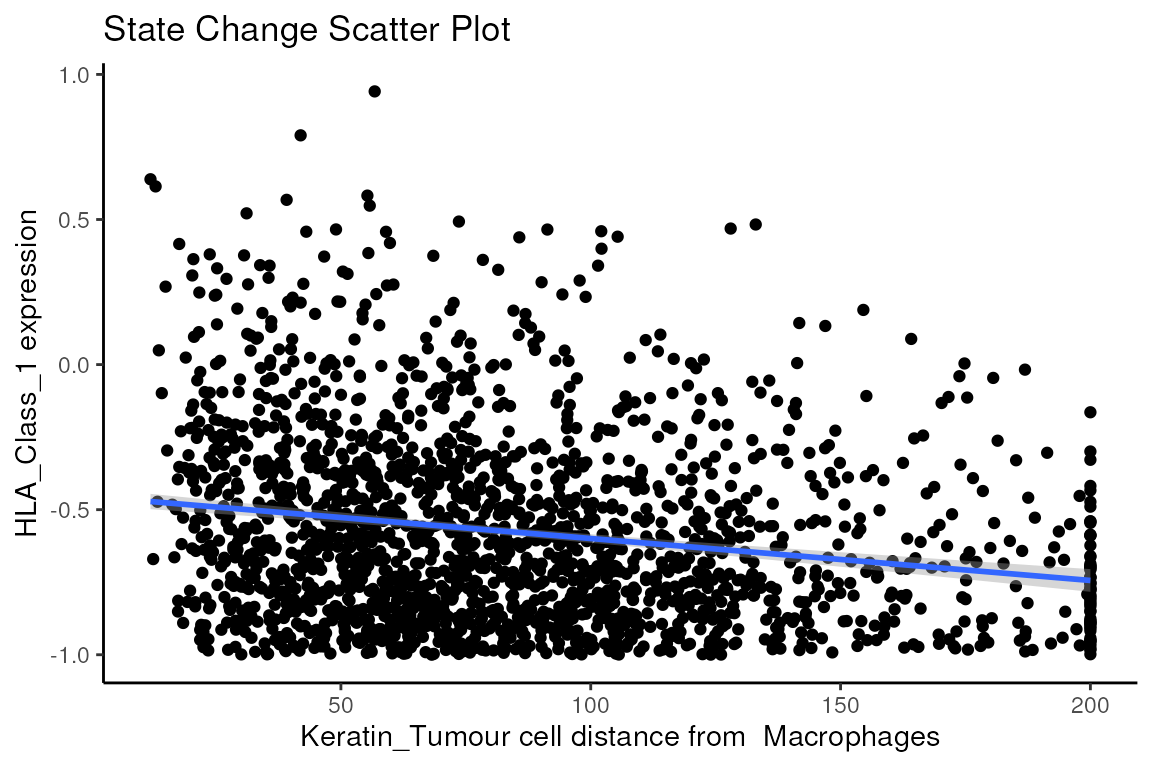
Now, we can take a look at the top 10 most significant results across all images.
stateChanges |> head(n = 10)
#> imageID primaryCellType otherCellType marker coef
#> 71820 37 Endothelial Tumour Lag3 -0.001621517
#> 146511 11 Neutrophils NK CD56 -0.059936866
#> 19570 35 CD4_T_cell B_cell CD20 -0.029185750
#> 19666 35 CD4_T_cell DC_or_Mono CD20 0.019125946
#> 5707 35 B_cell DC_or_Mono phospho.S6 0.005282065
#> 19675 35 CD4_T_cell DC_or_Mono phospho.S6 0.004033218
#> 5701 35 B_cell DC_or_Mono HLA.DR 0.011120703
#> 5859 35 B_cell Other_Immune P 0.011182182
#> 19522 35 CD4_T_cell dn_T_cell CD20 0.016349492
#> 5704 35 B_cell DC_or_Mono H3K9ac 0.005096632
#> tval pval fdr
#> 71820 -5.639068e+14 0.000000e+00 0.000000e+00
#> 146511 -4.011535e+16 0.000000e+00 0.000000e+00
#> 19570 -4.057355e+01 7.019343e-282 4.104561e-277
#> 19666 4.053436e+01 1.891267e-281 8.294389e-277
#> 5707 4.041385e+01 5.306590e-278 1.861817e-273
#> 19675 3.472882e+01 4.519947e-219 1.321520e-214
#> 5701 3.415344e+01 8.401034e-212 2.105359e-207
#> 5859 3.414375e+01 1.056403e-211 2.316494e-207
#> 19522 3.391901e+01 1.219488e-210 2.376985e-206
#> 5704 3.399856e+01 3.266533e-210 5.730315e-206Immediately, we can appreciate that a couple of interactions appear a bit strange. One of the most significant interactions occurs between B cells and CD4 T cells, where CD4 T cells are found to increase in CD20 expression when in close proximity to B cells. Biologically, CD20 is a highly specific ligand for B cells, and under healthy circumstances are usually not expressed in T cells.
Could this potentially be an artefact of
calcStateChanges? We can examine the image through the
plotStateChanges function, where we indeed observe an
apparent localisation between B cells and T cells.
Question
Are there any other interactions here that you think might not make biological sense?
Does the relationship between T cell CD20 expression and B cell proximity occur across images?
-
Why are the majority of most significant interactions occurring in image 35?
HINT: Configure the parameters of
plotStateChangesto examine some these other significant interactions. Do they look like artefacts?
p <- plotStateChanges(
cells = kerenSPE,
type = "distances",
image = "35",
from = "CD4_T_cell",
to = "B_cell",
marker = "CD20",
size = 1,
shape = 19,
interactive = FALSE,
plotModelFit = FALSE,
method = "lm")
p$image +
labs(y = "CD20 expression in CD4_T_cell",
x = "Distance of B_cell to CD4_T_cell")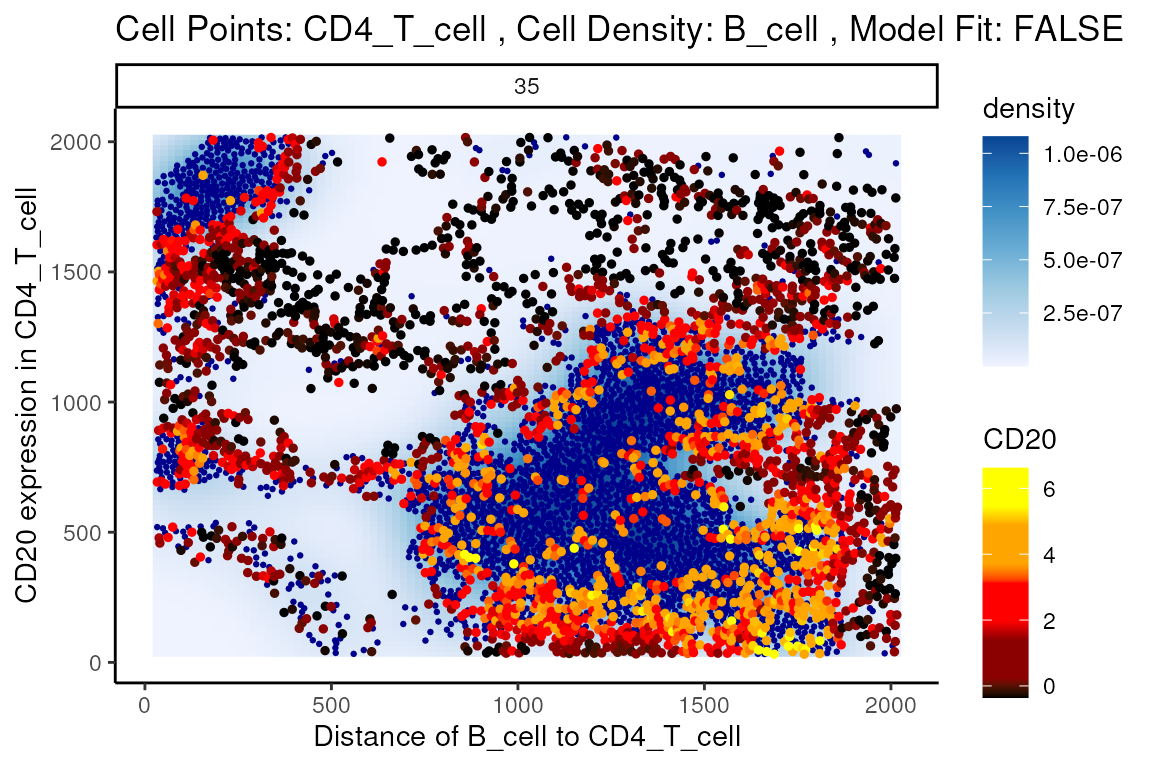
p$scatter
#> `geom_smooth()` using formula = 'y ~ x'
#> Warning: Removed 26 rows containing missing values (`geom_smooth()`).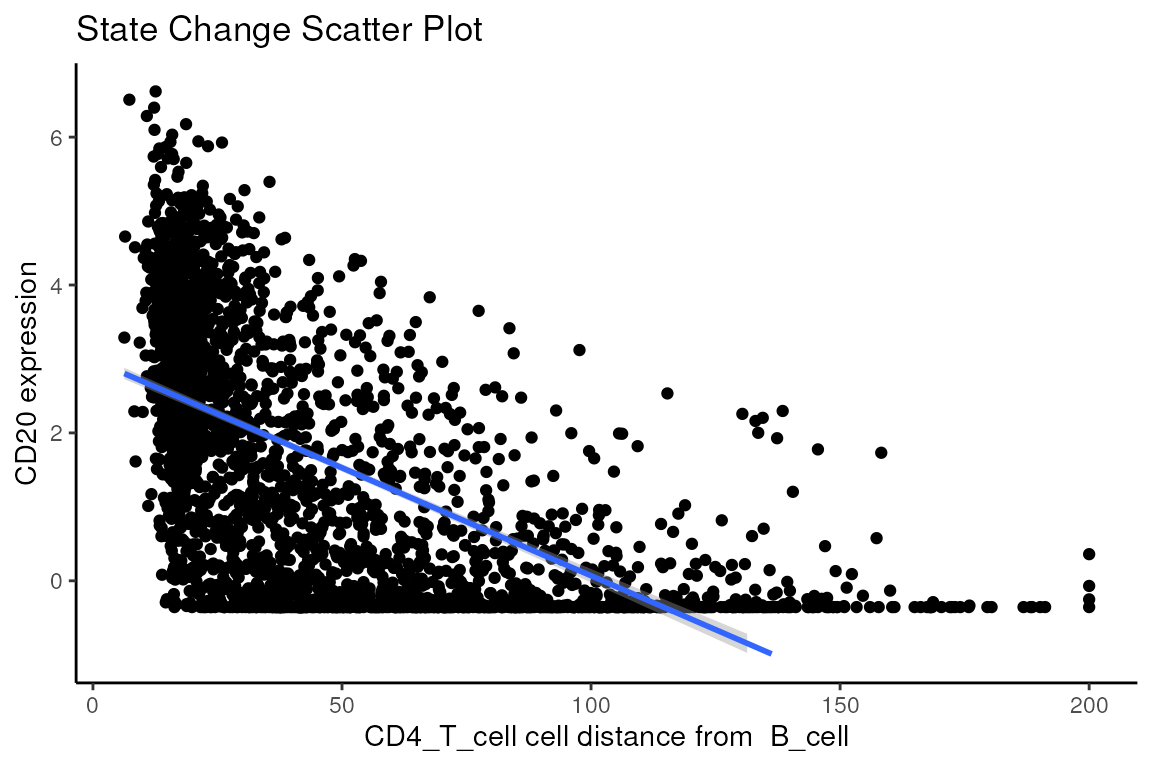
So why are T cells expressing CD20? This brings us to a key limitation of cell segmentation.
Contamination (Lateral marker spill over)
Contamination, or more specifically known as lateral marker spill over, is an issue that results in a cell’s marker expressions being wrongly attributed to another adjacent cell. This issue arises from incorrect segmentation where components of one cell are wrongly determined as belonging to another cell. Alternatively, this issue can arise when antibodies used to tag and measure marker expressions do not latch on properly to a cell of interest, thereby resulting in residual markers being wrongly assigned as belonging to a cell near the intended target cell. It is important that we either correct or account for this incorrect attribution of markers in our modelling process. This is critical in understanding whether significant cell-cell interactions detected are an artifact of technical measurement errors driven by spill over or are real biological changes that represent a shift in a cell’s state.
To circumvent this problem, Statial provides a function that predicts
the probability that a cell is any particular cell type -
calcContamination. calcContamination returns a
dataframe of probabilities demarcating the chance of a cell being any
particular cell type. This dataframe is stored under
contaminations in the reducedDim slot of the
SpatialExperiment object. It also provides the
rfMainCellProb column, which provides the probability that
a cell is indeed the cell type it has been designated. E.g. For a cell
designated as a CD8+ T cell, rfMainCellProb could give a 80% chance that
the cell is indeed CD8+ T cell, due to contamination.
We can then introduce these probabilities as covariates into our
linear model by setting contamination = TRUE as a parameter
in our calcStateChanges function. However, this is not a
perfect solution for the issue of contamination. As we can see, despite
factoring in contamination into our linear model, the correlation
between B cell density and CD20 expression in CD4+ T cells remains one
of the most significant interactions in our model.
kerenSPE <- calcContamination(kerenSPE)
#> Growing trees.. Progress: 31%. Estimated remaining time: 1 minute, 11 seconds.
#> Growing trees.. Progress: 61%. Estimated remaining time: 40 seconds.
#> Growing trees.. Progress: 92%. Estimated remaining time: 8 seconds.
stateChangesCorrected <- calcStateChanges(
cells = kerenSPE,
type = "distances",
minCells = 100,
contamination = TRUE)
stateChangesCorrected |> head(n = 20)
#> imageID primaryCellType otherCellType marker coef
#> 71820 37 Endothelial Tumour Lag3 -0.001621517
#> 146511 11 Neutrophils NK CD56 -0.059936866
#> 19570 35 CD4_T_cell B_cell CD20 -0.025259095
#> 19666 35 CD4_T_cell DC_or_Mono CD20 0.016327578
#> 19675 35 CD4_T_cell DC_or_Mono phospho.S6 0.003669318
#> 19522 35 CD4_T_cell dn_T_cell CD20 0.013945160
#> 5707 35 B_cell DC_or_Mono phospho.S6 0.004314204
#> 74980 3 Keratin_Tumour DC Ca -0.014138595
#> 19525 35 CD4_T_cell dn_T_cell HLA.DR 0.010418487
#> 5329 28 B_cell NK Na -0.004420442
#> 87358 23 Keratin_Tumour Unidentified HLA_Class_1 0.003170126
#> 5557 35 B_cell dn_T_cell HLA.DR 0.009055299
#> 86254 20 Keratin_Tumour Tumour HLA_Class_1 0.002928510
#> 87017 21 Keratin_Tumour DC Pan.Keratin -0.005984306
#> 5701 35 B_cell DC_or_Mono HLA.DR 0.008879957
#> 19531 35 CD4_T_cell dn_T_cell phospho.S6 0.002993069
#> 19659 35 CD4_T_cell DC_or_Mono CSF.1R 0.008576773
#> 76945 6 Keratin_Tumour Unidentified Na 0.004202852
#> 5899 35 B_cell Other_Immune phospho.S6 0.004611686
#> 86209 20 Keratin_Tumour Tumour Na 0.002523526
#> tval pval fdr
#> 71820 -4.413449e+14 0.000000e+00 0.000000e+00
#> 146511 -2.255870e+17 0.000000e+00 0.000000e+00
#> 19570 -3.544409e+01 2.333406e-226 1.364459e-221
#> 19666 3.431352e+01 1.548676e-214 6.791913e-210
#> 19675 3.014604e+01 2.225797e-172 7.809208e-168
#> 19522 3.006185e+01 1.488843e-171 4.353005e-167
#> 5707 2.992223e+01 2.374401e-169 5.950420e-165
#> 74980 -3.002240e+01 1.277905e-166 2.802207e-162
#> 19525 2.919115e+01 4.371259e-163 8.520313e-159
#> 5329 -2.879238e+01 2.297711e-155 4.030759e-151
#> 87358 2.570978e+01 1.360502e-133 2.169691e-129
#> 5557 2.600769e+01 9.094754e-133 1.329539e-128
#> 86254 2.555689e+01 6.903035e-132 9.315114e-128
#> 87017 -2.465210e+01 2.611049e-126 3.158630e-122
#> 5701 2.528087e+01 2.700838e-126 3.158630e-122
#> 19531 2.514130e+01 1.579188e-125 1.731432e-121
#> 19659 2.508207e+01 5.285961e-125 5.454646e-121
#> 76945 2.465754e+01 1.954359e-123 1.904686e-119
#> 5899 2.467994e+01 5.003979e-121 4.620121e-117
#> 86209 2.421095e+01 1.429013e-119 1.253423e-115However, this does not mean factoring in contamination into our linear model was ineffective. In general, cell type specific markers such as CD68, CD45, and CD20 should not change in cells they are not specific to. Therefore, relationships detected to be significant involving these cell type markers are likely false positives and will be treated as such for the purposes of evaluation.
Plotting the relationship between false positives and true positives, we’d expect the contamination correction to be greatest in relationships which are detected to be more significant.
cellTypeMarkers <- c("CD3", "CD4", "CD8", "CD56", "CD11c", "CD68", "CD45", "CD20")
values = c("blue", "red")
names(values) <- c("None", "Corrected")
df <- rbind(data.frame(TP =cumsum(stateChanges$marker %in% cellTypeMarkers), FP = cumsum(!stateChanges$marker %in% cellTypeMarkers), type = "None"),
data.frame(TP =cumsum(stateChangesCorrected$marker %in% cellTypeMarkers), FP = cumsum(!stateChangesCorrected$marker %in% cellTypeMarkers), type = "Corrected"))
ggplot(df, aes(x = TP, y = FP, colour = type)) + geom_line()+ labs(y = "Cell state marker", x = "Cell type marker") + scale_colour_manual(values = values)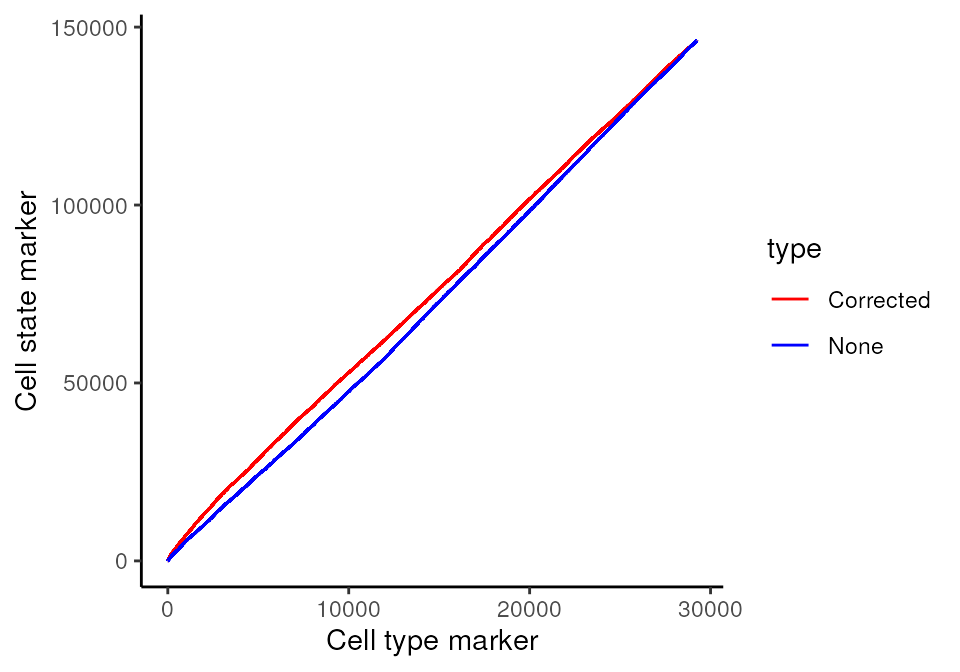
Here, we zoom in on the ROC curve where the top 100 lowest p values occur, where we indeed see more true positives than false positives with contamination correction.
ggplot(df, aes(x = TP, y = FP, colour = type)) + geom_line()+ xlim(0,100) + ylim(0,1000)+ labs(y = "Cell state marker", x = "Cell type marker") + scale_colour_manual(values = values)
#> Warning: Removed 348999 rows containing missing values (`geom_line()`).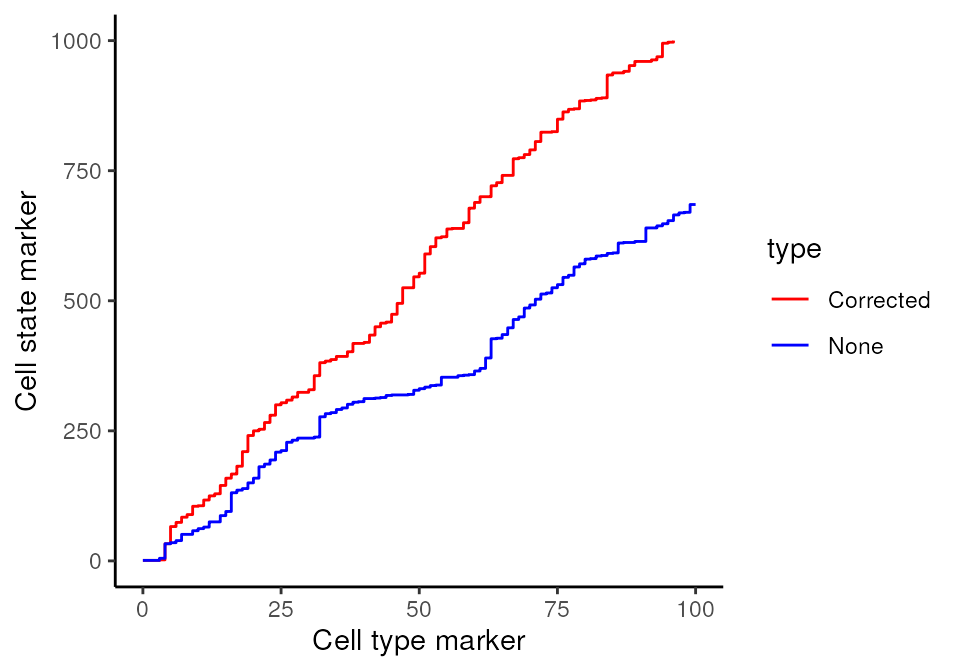
Question
- What can we conclude from the above ROC graphs?
Associate continuous state changes with survival outcomes
Similiar to Kontextual, we can run a similar survival
analysis using our state changes results. Here, prepMatrix
extracts the coefficients, or the coef column of
stateChanges by default. To use the t values instead,
specify column = "tval" in the prepMatrix
function.
# Preparing features for Statial
stateMat <- prepMatrix(stateChanges)
# Ensuring rownames of stateMat match up with rownames of the survival vector
stateMat <- stateMat[names(kerenSurv), ]
# Remove some very small values
stateMat <- stateMat[,colMeans(abs(stateMat)>0.0001)>.8]
survivalResults <- colTest(stateMat, kerenSurv, type = "survival")
head(survivalResults)
#> coef se.coef pval adjPval
#> Keratin_Tumour__Mesenchymal__HLA_Class_1 -800 230 0.0005 0.28
#> Macrophages__Endothelial__CD31 -390 120 0.0019 0.28
#> Macrophages__dn_T_cell__P -400 130 0.0026 0.28
#> Macrophages__CD4_T_cell__H3K9ac -560 190 0.0029 0.28
#> Keratin_Tumour__dn_T_cell__HLA_Class_1 -560 190 0.0032 0.28
#> Keratin_Tumour__Keratin_Tumour__phospho.S6 170 59 0.0040 0.28
#> cluster
#> Keratin_Tumour__Mesenchymal__HLA_Class_1 Keratin_Tumour__Mesenchymal__HLA_Class_1
#> Macrophages__Endothelial__CD31 Macrophages__Endothelial__CD31
#> Macrophages__dn_T_cell__P Macrophages__dn_T_cell__P
#> Macrophages__CD4_T_cell__H3K9ac Macrophages__CD4_T_cell__H3K9ac
#> Keratin_Tumour__dn_T_cell__HLA_Class_1 Keratin_Tumour__dn_T_cell__HLA_Class_1
#> Keratin_Tumour__Keratin_Tumour__phospho.S6 Keratin_Tumour__Keratin_Tumour__phospho.S6For our state changes results,
Keratin_Tumour__Mesenchymal__HLA_Class_1 is the most
significant pairwise relationship which contributes to patient survival.
That is, the relationship between HLA class I expression in
keratin/tumour cells and their spatial proximity to mesenchymal cells.
As there is a negative coeffcient associated with this relationship,
which tells us that higher HLA class I expression in keratin/tumour
cells nearby mesenchymal cell populations lead to poorer survival
outcomes for patients.
# Selecting the most significant relationship
survRelationship = stateMat[["Keratin_Tumour__Mesenchymal__HLA_Class_1"]]
survRelationship = ifelse(survRelationship > median(survRelationship), "Higher expressed in close cells", "Lower expressed in close cells")
# Plotting Kaplan-Meier curve
survfit2(kerenSurv ~ survRelationship) |>
ggsurvfit() +
add_pvalue() +
ggtitle("Keratin_Tumour__Mesenchymal__HLA_Class_1")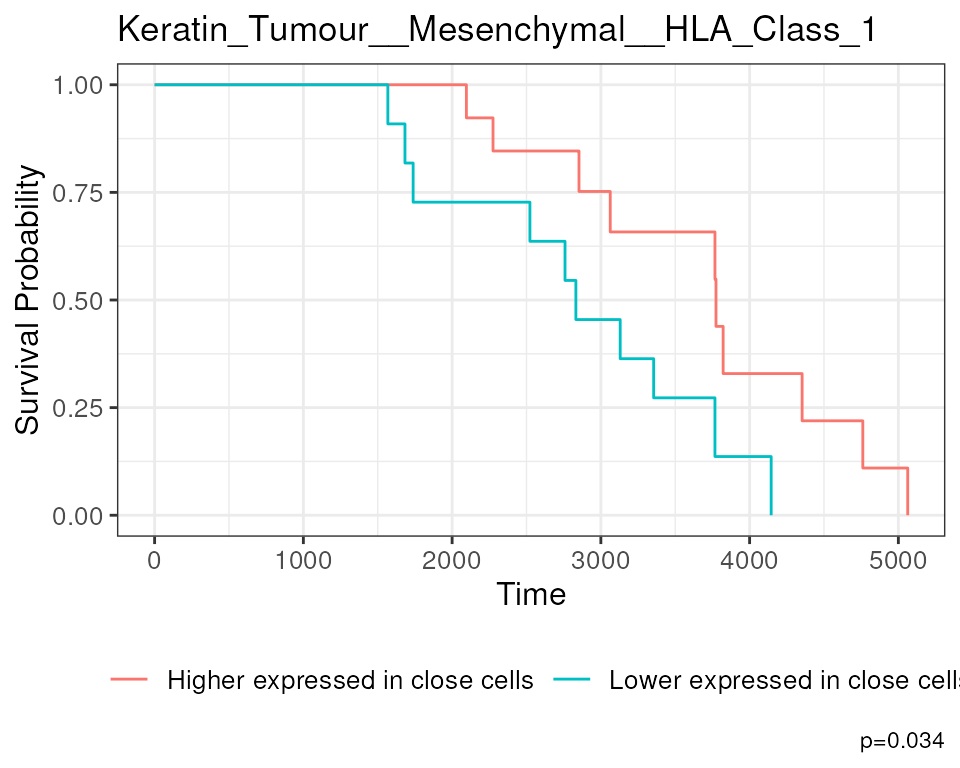
Question
- How should these coefficients be interpreted?
- Do any of these relationships makes sense?
- Could you visualise representative images?
Continuous cell state changes within spatial domains
We can look at changes of cell state relative to membership of different spatial domains. These domains can represent distinct tissue microenvironments where cells will potentially be interacting with different types cells.
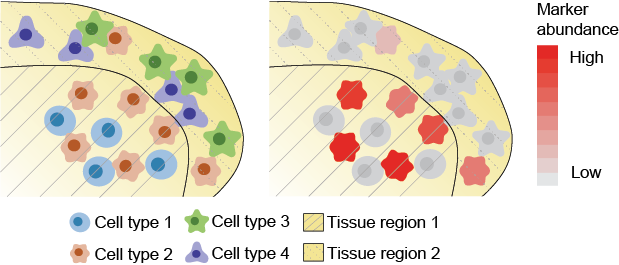
Here we see the abundance of a marker being higher in cell type 2 within spatial region 1 than spatial region 2.
Identify spatial domains with lisaClust
We can cluster areas with similar spatial interactions to identify
regions using the lisaClust package on Bioconductor. Here
we set k = 5 to identify 5 regions.
set.seed(51773)
# Preparing features for lisaClust
kerenSPE <- lisaClust::lisaClust(kerenSPE, k = 5)
#> Generating local L-curves. If you run out of memory, try 'fast = FALSE'.The regions identified by lisaClust can be visualised using the
hatchingPlot function.
# Use hatching to visualise regions and cell types.
lisaClust::hatchingPlot(kerenSPE,
useImages = "5",
line.spacing = 41, # spacing of lines
nbp = 100 # smoothness of lines
)
#> There is no cellID. I'll create these
#> There is no image specific imageCellID. I'll create these
#> Creating variable region
#> Concave windows are temperamental. Try choosing values of window.length > and < 1 if you have problems.
#> Warning in split.default(x = seq_len(nrow(x)), f = f, drop = drop, ...): data
#> length is not a multiple of split variable
#> Warning in split.default(x = seq_len(nrow(x)), f = f, drop = drop, ...): data
#> length is not a multiple of split variable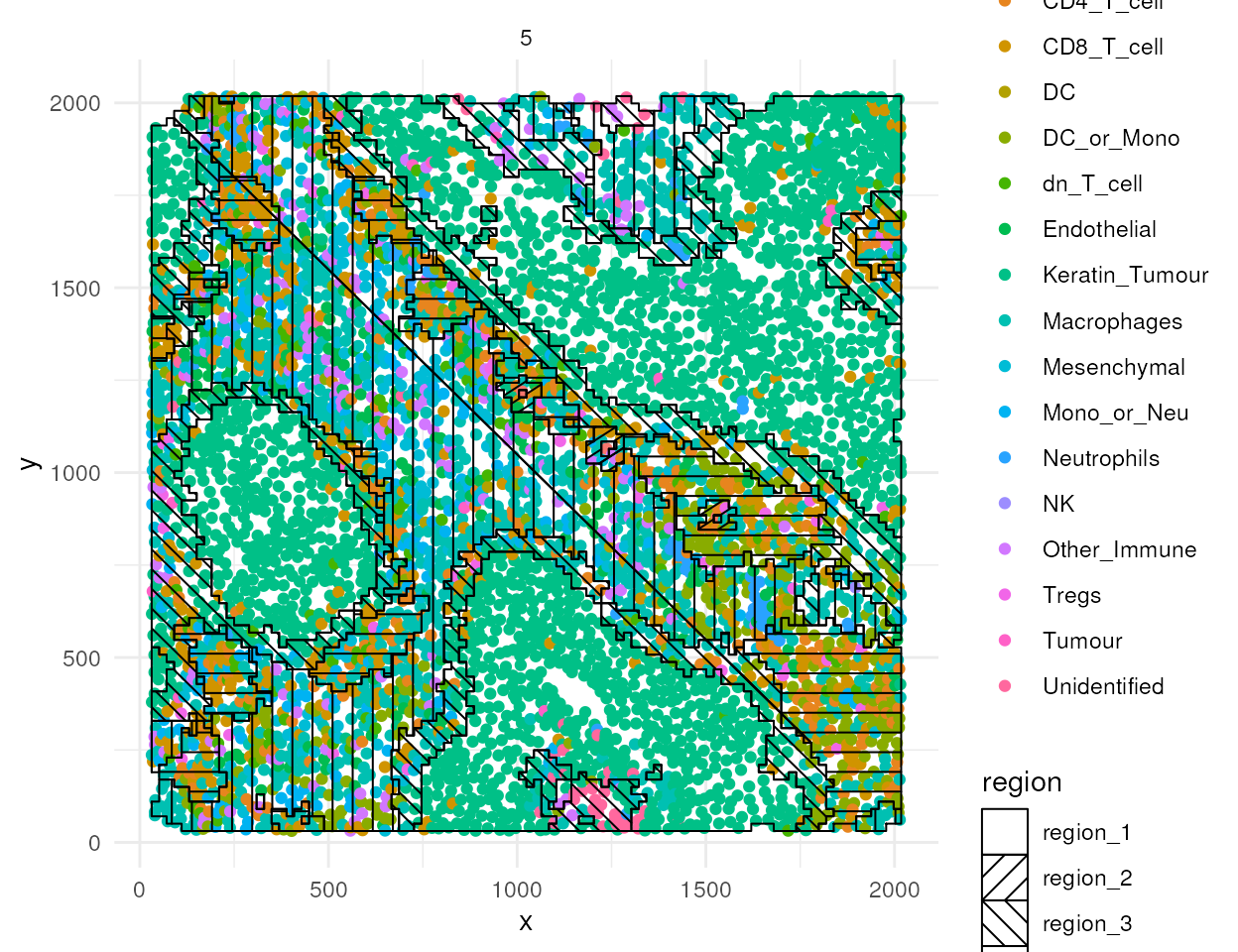
Changes in marker means
Statial provides functionality to identify the average
marker expression of a given cell type in a given region, using the
getMarkerMeans function. Similar to the analysis above,
these features can also be used for survival analysis.
cellTypeRegionMeans <- getMarkerMeans(kerenSPE,
imageID = "imageID",
cellType = "cellType",
region = "region")
survivalResults = colTest(cellTypeRegionMeans[names(kerenSurv),], kerenSurv, type = "survival")
head(survivalResults)
#> coef se.coef pval adjPval
#> phospho.S6__Unidentified__region_3 -3.10 0.86 0.00034 0.33
#> CD8__Mono_or_Neu__region_1 7.40 2.10 0.00041 0.33
#> Au__Tumour__region_3 0.97 0.29 0.00081 0.33
#> Ta__Tumour__region_3 0.95 0.29 0.00088 0.33
#> CD31__Mesenchymal__region_5 21.00 6.30 0.00110 0.33
#> P__Unidentified__region_3 -1.10 0.35 0.00130 0.33
#> cluster
#> phospho.S6__Unidentified__region_3 phospho.S6__Unidentified__region_3
#> CD8__Mono_or_Neu__region_1 CD8__Mono_or_Neu__region_1
#> Au__Tumour__region_3 Au__Tumour__region_3
#> Ta__Tumour__region_3 Ta__Tumour__region_3
#> CD31__Mesenchymal__region_5 CD31__Mesenchymal__region_5
#> P__Unidentified__region_3 P__Unidentified__region_3Patient classification
Finally we demonstrate how we can use the Bioconductor package
ClassifyR to perform patient classification with the
features generated from Statial. In addition to the
kontextual, state changes, and marker means values, we also calculate
cell type proportions and region proportions using the
getProp function in spicyR. Here we perform 5
fold cross validation with 20 repeats, using a CoxPH model for survival
classification.
# Calculate cell type and region proportions
cellTypeProp <- getProp(kerenSPE,
feature = "cellType",
imageID = "imageID")
regionProp <- getProp(kerenSPE,
feature = "region",
imageID = "imageID")
# Combine all the features into a list for classification
featureList <- list(states = stateMat,
kontextual = kontextMat,
regionMarkerMeans = cellTypeRegionMeans,
cellTypeProp = cellTypeProp,
regionProp = regionProp)
# Ensure the rownames of the features match the order of the survival vector
featureList <- lapply(featureList, function(x)x[names(kerenSurv),])
set.seed(51773)
kerenCV = crossValidate(
measurements = featureList,
outcome = kerenSurv,
classifier = "CoxPH",
selectionMethod = "CoxPH",
nFolds = 5,
nFeatures = 10,
nRepeats = 20
)Here, we use the performancePlot function to assess the
C-index from each repeat of the 5-fold cross-validation. We can see that
in this case cell type proportions are not a reliable predictor of
survival. However the proportion of each spatial domain region in an
image or the states estimated by Kontextual could be.
# Calculate AUC for each cross-validation repeat and plot.
performancePlot(kerenCV,
characteristicsList = list(x = "Assay Name")
) +
theme(axis.text.x = element_text(angle = 45, vjust = 1, hjust=1))
#> Warning in .local(results, ...): C-index not found in all elements of results.
#> Calculating it now.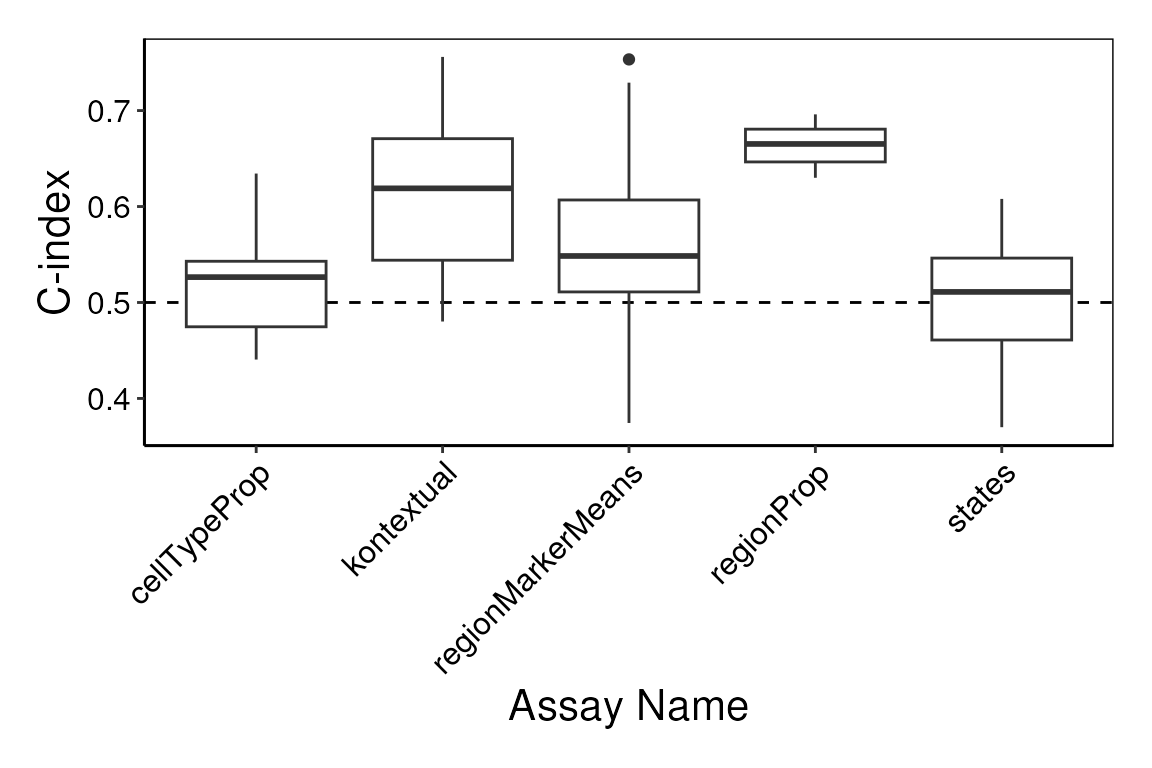
References
- Keren, L., Bosse, M., Marquez, D., Angoshtari, R., Jain, S., Varma, S., Yang, S. R., Kurian, A., Van Valen, D., West, R., Bendall, S. C., & Angelo, M. (2018). A Structured Tumor-Immune Microenvironment in Triple Negative Breast Cancer Revealed by Multiplexed Ion Beam Imaging. Cell, 174(6), 1373-1387.e1319. (DOI)
Session info
sessionInfo()
#> R version 4.3.1 (2023-06-16)
#> Platform: x86_64-pc-linux-gnu (64-bit)
#> Running under: Ubuntu 22.04.2 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.20.so; LAPACK version 3.10.0
#>
#> locale:
#> [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
#> [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
#> [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
#> [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
#> [9] LC_ADDRESS=C LC_TELEPHONE=C
#> [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: Etc/UTC
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats4 stats graphics grDevices utils datasets methods
#> [8] base
#>
#> other attached packages:
#> [1] StatialBioc2023_1.0.1 scater_1.29.3
#> [3] scuttle_1.11.2 ggsurvfit_0.3.0
#> [5] tidyr_1.3.0 dplyr_1.1.2
#> [7] SpatialExperiment_1.11.0 SingleCellExperiment_1.23.0
#> [9] ggplot2_3.4.3 ClassifyR_3.5.8
#> [11] survival_3.5-7 BiocParallel_1.35.3
#> [13] MultiAssayExperiment_1.27.0 SummarizedExperiment_1.31.1
#> [15] GenomicRanges_1.53.1 GenomeInfoDb_1.37.2
#> [17] IRanges_2.35.2 MatrixGenerics_1.13.1
#> [19] matrixStats_1.0.0 S4Vectors_0.39.1
#> [21] generics_0.1.3 lisaClust_1.9.1
#> [23] spicyR_1.12.1 Statial_1.2.2
#> [25] Biobase_2.61.0 BiocGenerics_0.47.0
#>
#> loaded via a namespace (and not attached):
#> [1] splines_4.3.1 bitops_1.0-7
#> [3] tibble_3.2.1 R.oo_1.25.0
#> [5] polyclip_1.10-4 lifecycle_1.0.3
#> [7] rstatix_0.7.2 edgeR_3.43.8
#> [9] rprojroot_2.0.3 lattice_0.21-8
#> [11] MASS_7.3-60 backports_1.4.1
#> [13] magrittr_2.0.3 limma_3.57.7
#> [15] plotly_4.10.2 sass_0.4.7
#> [17] rmarkdown_2.24 jquerylib_0.1.4
#> [19] yaml_2.3.7 spatstat.sparse_3.0-2
#> [21] cowplot_1.1.1 minqa_1.2.5
#> [23] RColorBrewer_1.1-3 abind_1.4-5
#> [25] zlibbioc_1.47.0 purrr_1.0.2
#> [27] R.utils_2.12.2 RCurl_1.98-1.12
#> [29] tweenr_2.0.2 GenomeInfoDbData_1.2.10
#> [31] ggrepel_0.9.3 irlba_2.3.5.1
#> [33] spatstat.utils_3.0-3 pheatmap_1.0.12
#> [35] goftest_1.2-3 spatstat.random_3.1-5
#> [37] dqrng_0.3.0 pkgdown_2.0.7
#> [39] DelayedMatrixStats_1.23.4 codetools_0.2-19
#> [41] DropletUtils_1.21.0 DelayedArray_0.27.10
#> [43] ggforce_0.4.1 tidyselect_1.2.0
#> [45] farver_2.1.1 viridis_0.6.4
#> [47] lme4_1.1-34 ScaledMatrix_1.9.1
#> [49] spatstat.explore_3.2-1 jsonlite_1.8.7
#> [51] BiocNeighbors_1.19.0 systemfonts_1.0.4
#> [53] tools_4.3.1 ragg_1.2.5
#> [55] Rcpp_1.0.11 glue_1.6.2
#> [57] gridExtra_2.3 SparseArray_1.1.11
#> [59] xfun_0.40 ranger_0.15.1
#> [61] mgcv_1.9-0 HDF5Array_1.29.3
#> [63] scam_1.2-14 withr_2.5.0
#> [65] numDeriv_2016.8-1.1 fastmap_1.1.1
#> [67] boot_1.3-28.1 rhdf5filters_1.13.5
#> [69] fansi_1.0.4 digest_0.6.33
#> [71] rsvd_1.0.5 R6_2.5.1
#> [73] textshaping_0.3.6 colorspace_2.1-0
#> [75] tensor_1.5 spatstat.data_3.0-1
#> [77] R.methodsS3_1.8.2 utf8_1.2.3
#> [79] data.table_1.14.8 class_7.3-22
#> [81] httr_1.4.7 htmlwidgets_1.6.2
#> [83] S4Arrays_1.1.5 pkgconfig_2.0.3
#> [85] gtable_0.3.3 XVector_0.41.1
#> [87] htmltools_0.5.6 carData_3.0-5
#> [89] scales_1.2.1 knitr_1.43
#> [91] reshape2_1.4.4 rjson_0.2.21
#> [93] curl_5.0.2 nlme_3.1-163
#> [95] nloptr_2.0.3 cachem_1.0.8
#> [97] rhdf5_2.45.1 stringr_1.5.0
#> [99] vipor_0.4.5 parallel_4.3.1
#> [101] concaveman_1.1.0 desc_1.4.2
#> [103] pillar_1.9.0 grid_4.3.1
#> [105] vctrs_0.6.3 ggpubr_0.6.0
#> [107] car_3.1-2 BiocSingular_1.17.1
#> [109] beachmat_2.17.15 beeswarm_0.4.0
#> [111] evaluate_0.21 magick_2.7.5
#> [113] cli_3.6.1 locfit_1.5-9.8
#> [115] compiler_4.3.1 rlang_1.1.1
#> [117] crayon_1.5.2 ggsignif_0.6.4
#> [119] labeling_0.4.2 plyr_1.8.8
#> [121] fs_1.6.3 ggbeeswarm_0.7.2
#> [123] stringi_1.7.12 viridisLite_0.4.2
#> [125] deldir_1.0-9 lmerTest_3.1-3
#> [127] munsell_0.5.0 lazyeval_0.2.2
#> [129] spatstat.geom_3.2-4 V8_4.3.3
#> [131] Matrix_1.6-1 sparseMatrixStats_1.13.4
#> [133] Rhdf5lib_1.23.0 statmod_1.5.0
#> [135] highr_0.10 broom_1.0.5
#> [137] memoise_2.0.1 bslib_0.5.1